
在收发数据时,像蓝牙,数据往往封装成某种格式的消息。lipdp是用于封装消息的一种格式。这格式名称来自“Leagor IP Discovery Protocol(LIPDP)”。
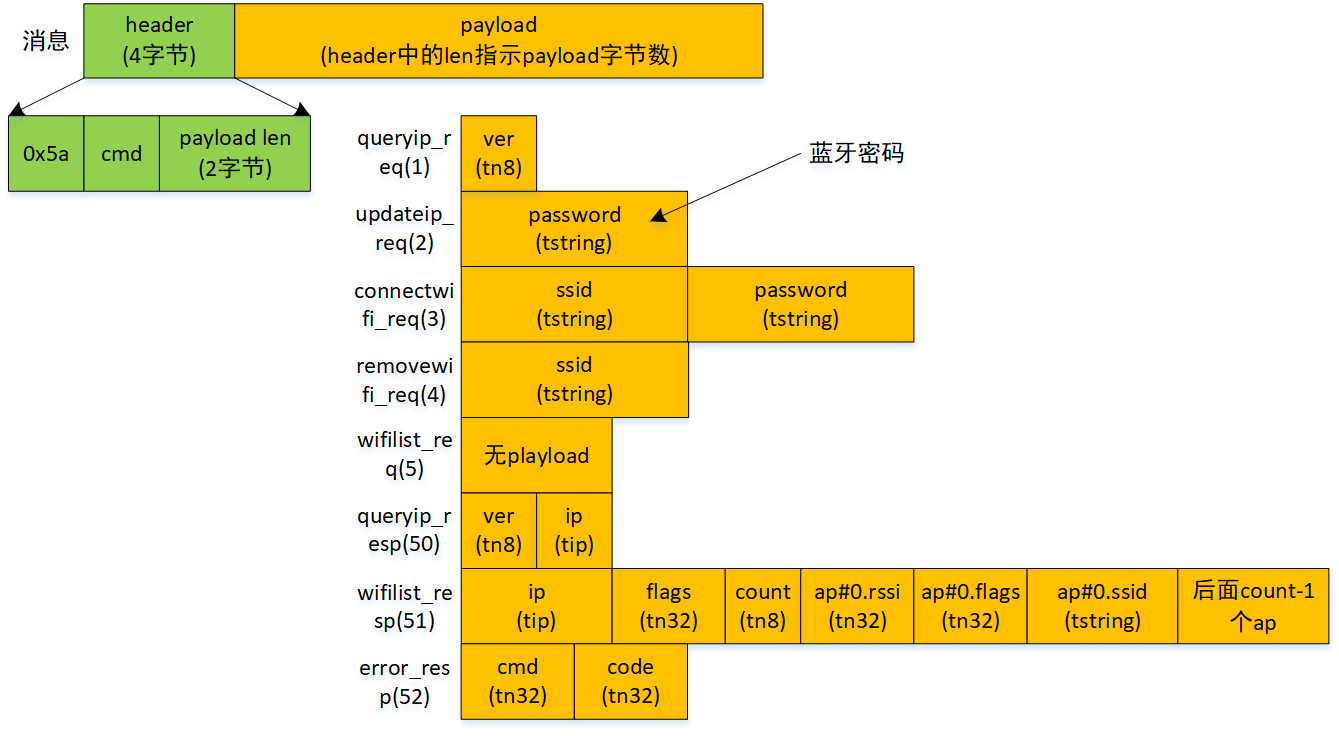
图1是数个lipdp格式的消息示例。
- header。头部有4个字节:一个固定值的前导字节、消息码(cmd)、payload字节数。
- payload。负载可以任意长度,包括0。header中两个字节指示了payload块的字节数。负载由若干个单元组成。
payload单元的第一个字节指示单元类型,后面字节是什么内容依赖单元类型,目前支持7种类型。
| 类型 | 名称 | 字节数 | 描述 |
| lipdp_tn8(0) | 1字节整数 | 1 | int8_t |
| lipdp_tn32(1) | 4字节整数 | 4 | int32_t,小端序 |
| lipdp_tn64(2) | 8字节整数 | 8 | int64_t,小端序 |
| lipdp_tstring(3) | 不含'\0'的字符串 | 可变 | 串中不能含有'\0',末尾会加'\0' |
| lipdp_thexstring(4) | hex二进制数据 | 可变 | 以十六进制字符串表示的二进制数据(注1) |
| lipdp_tbinary(5) | 二进制数据 | 可变 | 先二字节表示长度,然后二进制数据 |
| lipdp_tip(6) | IP地址 | 1/5/17 | 先1字节类型,然后数值。没有可用网络/ipv4/ipv6 |
注1:真到发送时不会出现lipdp_thexstring,存在它只是方便编写代码。举个例子,要表示“4b010100cf”这5字节的二进制数据,c语言可用一个uint8_t数组,一些脚本语言就不那么方便了,这时可让允许书写为字符串“4b010100cf”,然后送给lipdp解释器。解释器发现它是lipdp_thexstring,最终会把它转换为lipdp_tbinary。为什么不是lipdp_tstring?——lipdp_tstring判断长度的方法是遇到“\0”,即内容不能出现“\0”,而lipdp_thexstring成为二进制后,是有可能出现“\0”的。
local len, wrote = aplt.vdata_:write_lipdp(1, {
{rose.lipdp_tn8, 1},
{rose.lipdp_tn32, 0xfe123456},
{rose.lipdp_tstring, "5a01010001"},
{rose.lipdp_tstring, ""},
{rose.lipdp_thexstring, "4b010100cf"},
{rose.lipdp_thexstring, ""},
{rose.lipdp_tip, rose.LEAGOR_BLE_AF_INET, 0x7301a8c0},
});
-- 4: LEAGOR_BLE_MTU_HEADER_SIZE
local lipdp = aplt.vdata_:read_lipdp(len - wrote + 4);以上lua脚本用于生成一个lipdp消息,cmd是1,负载含有7个单元。以下是这个消息在内存中的字节流。
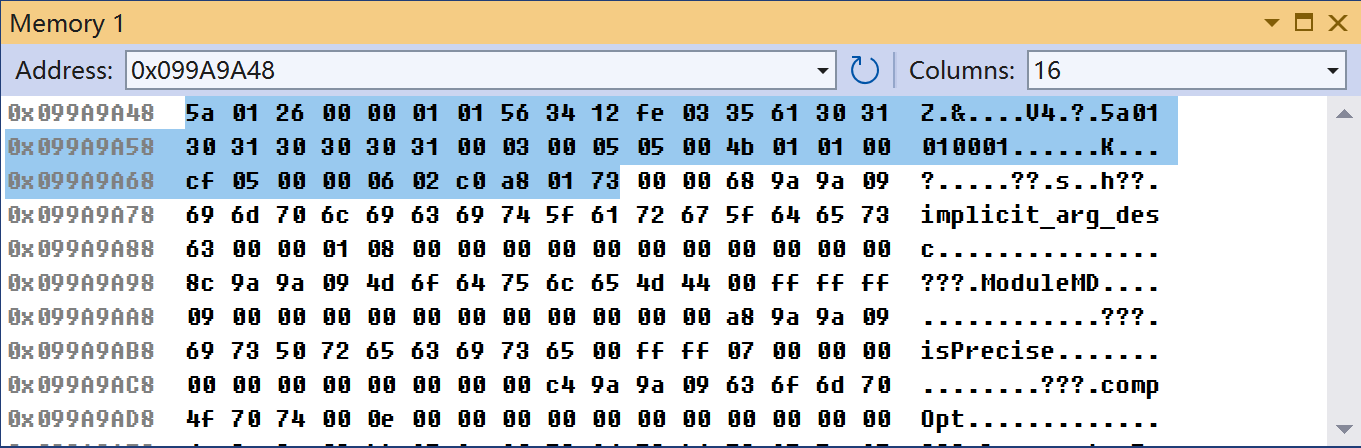
- 5a 01 26 00。header。cmd是1,负载长度38字节。
- 00 01。第一单元。类型tn8,数值1。
- 01 56 34 12 fe。第二单元。类型tn32,数值0xfe123456。
- 03 35 61 30 31 30 31 30 30 30 31 00。第三单元。类型tstring,字符串“5a01010001”。
- 03 00。第四单元。类型tstring,空字符串。
- 05 05 00 4b 01 01 01 00 cf。第五单元。代码写的是thexstring,翻译成tbinary,二进制数值{0x4b, 0x01, 0x01, 0x00, 0xcf}。“05 00”指示了该单元中字节数。
- 05 00 00。第六单元。代码写的是thexstring,翻译成tbinary,0字节数据。
- 06 02 c0 a8 01 73。第七单元。类型tip,02表示该IP类型是ipv4(LEAGOR_BLE_AF_INET),后面4字节是ipv4地址。
vdata提供了read_lipdp方法,功能是把lipdp格式的一块内存转换为一个lua变量。
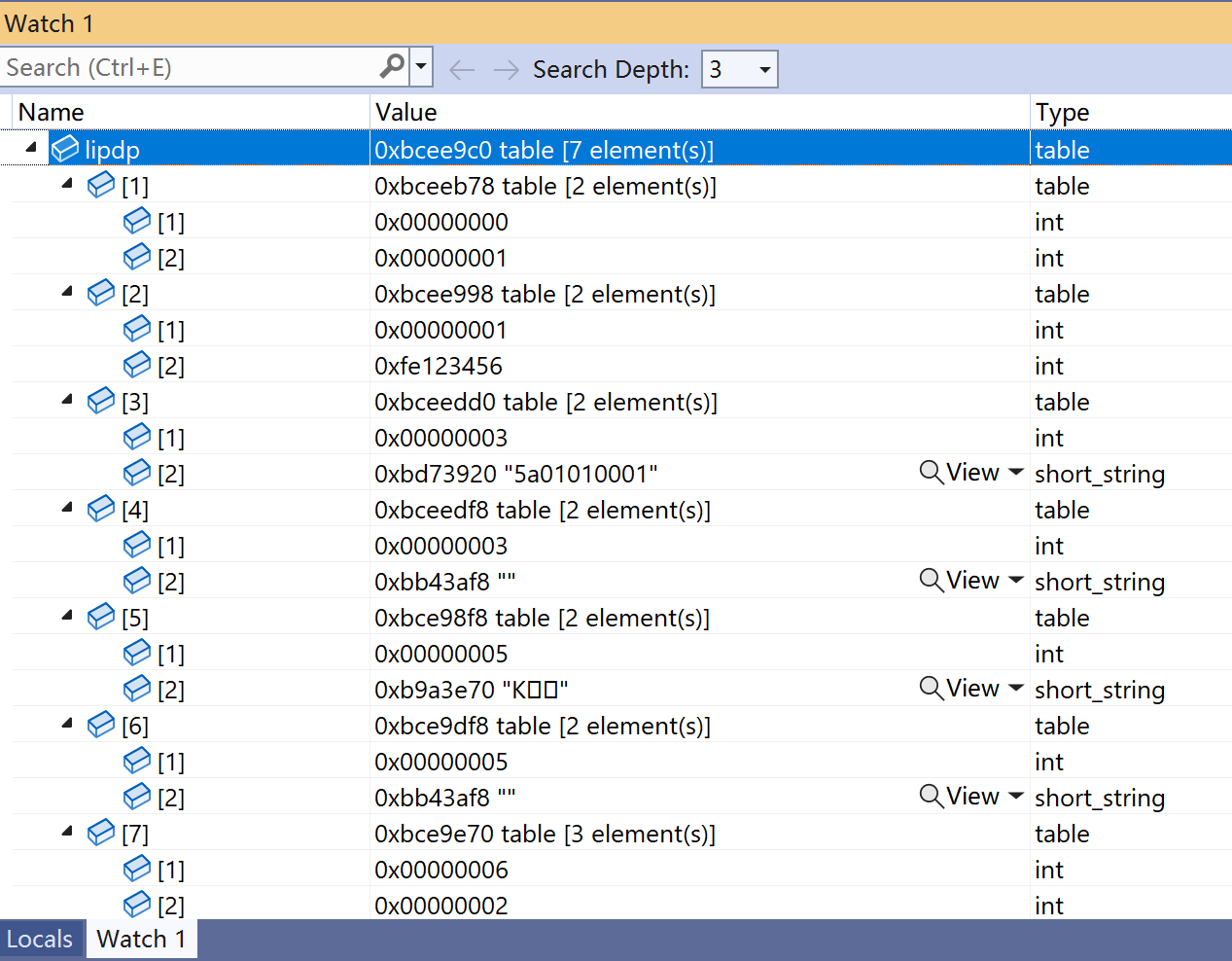
图3是上面代码中,紧接调用read_lipdp(len - wrote + 4)生成的lipdp变量。lipdp自身是一个数组表,然后每个单元是一个数组表。
一、tlipdp_packer、tlipdp_parser
tlipdp_packer、tlipdp_parser是rose为处理lipdp格式,提供的两个c++类。
tlipdp_packer用于将cmd、若干单元打包成消息。tlipdp_parser则是逆方向,从消息解析出cmd、若干单元。
不论打包还是解析,都用了中间格式:tlipdp_item。使用tlipdp_item一分为三步。
- 定义items、tlipdp_items_lock、index、payload_len。
- 使用LIPDP_PUSH_ITEM_xxx向负载增加单元。这些单元会放在items数组。
- 调用packer.items_2_data,由items数组生成负载、加上cmd,从而生成一个表示该消息内存块。返回值是该消息字节数。
void pack_sample(tuint8data& result)
{
tlipdp_packer packer;
tlipdp_item* items = nullptr;
int item_count = 7;
tlipdp_items_lock lock(item_count, &items);
int index = 0;
int payload_len = 0;
LIPDP_PUSH_ITEM_n8(1);
LIPDP_PUSH_ITEM_n32(0xfe123456);
LIPDP_PUSH_ITEM_string("5a01010001");
LIPDP_PUSH_ITEM_string("");
LIPDP_PUSH_ITEM_hexstring("4b010100cf");
LIPDP_PUSH_ITEM_hexstring("");
LIPDP_PUSH_ITEM_ipv4(0x7301a8c0);
VALIDATE(index == item_count, null_str);
int packet_len = packer.items_2_data(msg_queryip_resp, payload_len, items, item_count);
result.ptr = packer.packet_data_;
result.len = packet_len;
}这个用C写的函数能打包出一条和上面lua代码一样的消息。在内部,vdata::write_lipdp(...)就是靠着这样的C代码实现打包。
LIPDP_PUSH_ITEM_xxx有着差不多逻辑,以下是LIPDP_PUSH_ITEM_string。
#define LIPDP_PUSH_ITEM_string(_data, _len) \ items[index].type = lipdp_tstring; \ items[index].data = (const uint8_t*)(_data); \ items[index].int32 = _len; \ payload_len += 1 + items[index].int32 + 1; \ index ++;
把单元内容存储到items[index]后,它们会连带着修改index、payload_len。后绪items_2_data须要提供payload_len参数,4+payload_len就是该消息字节数。
tlipdp_item不会复制字符串、二进制数据,所以必须在字符串、二进制数据还有效前,调用items_2_data。
二、tlipdp_receiver::enqueue
tipdp_receiver缓存、消费数据都是在一个叫enqueue的函数内进行。
void tlipdp_receiver::enqueue(const uint8_t* data, int len); std::function<void (int cmd, const uint8_t* data, int len)> did_read_;
- app收到数据了,调用enqueue(data, len)。
- 在enqueue(data, len),根据规则不断提取消息。提取到一个消息后,调用app提供的did_read_。
- did_read_是app提供的,执行着如何消费消息。有三个参数,cmd是藏在头中的命令,data是payload开始地址,len是payload字节数。
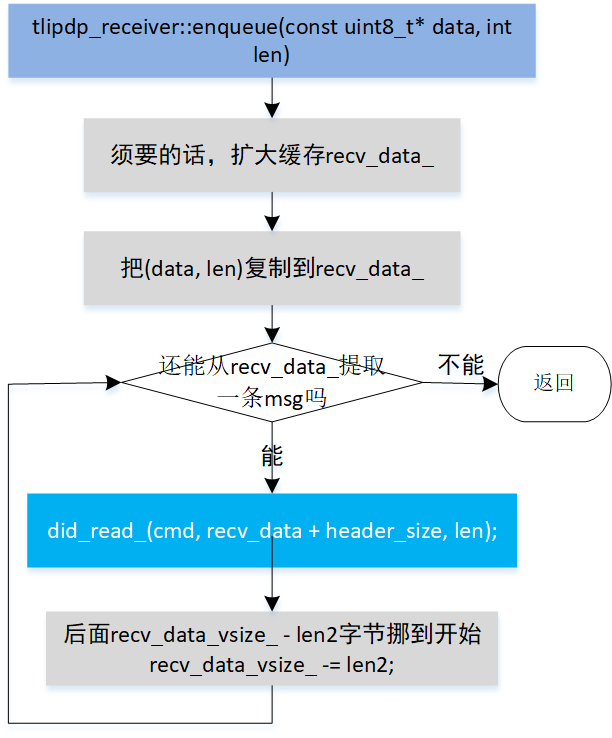
enqueue一个任务是提取消息,要做到不出错,又快,提取用了两重判断。1)消息必须以LEAGOR_BLE_PREFIX_BYTE开始。2)命令码必须是允许的命令码。——或许吧,为更准确,可能还得增加在注册允许的命令码时,增加指明该命令的payload字节数。
void tblebuf::enqueue(const uint8_t* data, int len)
{
VALIDATE(data != nullptr && len > 0, null_str);
const int min_size = posix_align_ceil(recv_data_vsize_ + len, 4096);
if (min_size > recv_data_size_) {
uint8_t* tmp = (uint8_t*)malloc(min_size);
if (recv_data_) {
if (recv_data_vsize_) {
memcpy(tmp, recv_data_, recv_data_vsize_);
}
free(recv_data_);
}
recv_data_ = tmp;
recv_data_size_ = min_size;
}(recv_data_, recv_data_size_)表示接收缓存。根据收到的数据长度自动扩大缓存。
memcpy(recv_data_ + recv_data_vsize_, data, len);
recv_data_vsize_ += len;
while (true) {
while (true) {
// 1. must prefix with LEAGOR_BLE_PREFIX_BYTE
int skip = 0;
for (int i = 0; i < recv_data_vsize_; i ++) {
if (recv_data_[i] == LEAGOR_BLE_PREFIX_BYTE) {
break;
}
skip ++;
}
if (skip && skip != recv_data_vsize_) {
memcpy(recv_data_, recv_data_ + skip, recv_data_vsize_ - skip);
}
recv_data_vsize_ -= skip;
if (recv_data_vsize_ < LEAGOR_BLE_MTU_HEADER_SIZE) { // payload len maybe is 0.
return;
}包头第一个字节必须是LEAGOR_BLE_PREFIX_BYTE。缓存中至少有包头字节数(LEAGOR_BLE_MTU_HEADER_SIZE)。
// 2. len
const int cmd = recv_data_[1];
if (recv_cmds_.count(cmd) == 0) {
// skip first. then again.
memcpy(recv_data_, recv_data_ + 1, recv_data_vsize_ - 1);
recv_data_vsize_ --;
continue;
}
const int len = posix_mku16(recv_data_[2], recv_data_[3]);
if (recv_data_vsize_ < LEAGOR_BLE_MTU_HEADER_SIZE + len) {
return;
}根据包头中命令进行判断。这些命令必须是已注册的recv_cmds_中的一个。
由包头提取出payload字节数后,缓存中至少有“包头+payload”字节数。
break;
}
const int cmd = recv_data_[1];
const int len = posix_mku16(recv_data_[2], recv_data_[3]);
const int len2 = LEAGOR_BLE_MTU_HEADER_SIZE + len;
VALIDATE(recv_data_vsize_ >= len2, null_str);
if (did_read_) {
did_read_(cmd, recv_data_ + LEAGOR_BLE_MTU_HEADER_SIZE, len);调用app提供的did_read_。这个len不是参数len,是从头中取出的payload字节数。len2则是“header+payload”的消息长度。

}
if (recv_data_vsize_ > len2) {
memcpy(recv_data_, recv_data_ + len2, recv_data_vsize_ - len2);
}
recv_data_vsize_ -= len2;既然已处理len2字节,把后面recv_data_vsize_ - len2字节向前挪到开始。

if (recv_data_vsize_ == 0) {
SDL_Log("tblebuf::enqueue(1.2): there is no extra data");
} else {
std::string str = rtc::hex_encode((const char*)recv_data_, recv_data_vsize_);
SDL_Log("tblebuf::enqueue(1.2): extra data: %s, recv_data_vsize_: %i", str.c_str(), recv_data_vsize_);
}
}
}