
下拉刷新会造成item_potion_.y小于0。出现item_potion_.y小于0会给现在实现的列表垃圾回收有啥影响,还不能确认。后面更新垃圾回收模块,需考虑这情况。
- 内容网格:程序中用于表示列表的结构。content_grid_表示内容网格。
- 视区:在窗口,由于展示列表的区域不能显示整个列表,当前正被看到的部分称为视区。content_表示视区。
- 视区偏移:视区在列表中偏移,记为item_position_(=content_.y - content_grid_.y),它的值>=0。视区偏移有垂直、水平两个方向,具体到这里只关心垂直偏移。为理解item_position_位置可参考图4。
- 操作区:内容网格中一块区域,渲染、设置左上角等操作只会发生在该区域中的行。gc_first_at_指示操作区的第一行,gc_last_at_指示最后一行。操作区矩形一定包含视区。
- 分配:该行要进入操作区了,意味着要显示,把非必要数据填向该行。回收:该行要离开操作区了,意味着不必显示该行,释放该行上的非必要数据。
由于列表特点,很多app会用它展示大数据,像聊天中历史记录,影视评论。在这些场景中,要处理的数据往往成百上千行,还是用一次性加载、一次性显示的话会占用大量内存、造成不好用户体验,甚至就不会成功,像内存不够了。改善它的相关技术合称单元自动回收,也称垃圾回收(Garbage Collection)。
回收目的是为了提高列表性能,提升性能总的来说表现在两个方面,一是耗更少内存,二是耗更少cpu。算法核心是任一时刻让存在一个操作区,渲染、设置左上角等操作只须处理这区域中的行。
一、哪些是垃圾数据
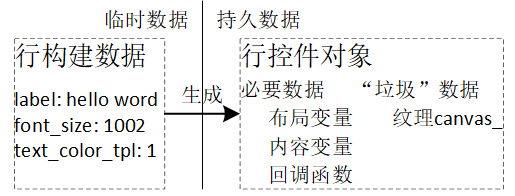
app产生“构建”行需要的数据,由它们生成行控件,一旦生成控件,“构建”数据往往就被释放了。垃圾收集算法实质是当行数超过N时,要释放资源,这资源可以有两种,一是整个行控件,二是控件中的非必要数据。相应地,按释放的是哪种资源分两种方案。
对第一种方案,一旦删除整个行控件,会引发一连串后果。1)app可能存有指向它的指针,那些针指将非法。2)app要访问该控件数据,但控件被删除了,需要额外逻辑。由于删除、重构控件是自动的,会给app编程带来很大不方便。
对第二种方案,控件中数据可分为必要数据、非必要数据。必要数据包括布局变量、内容变量、回调函数,等等。非必要数据包括为提高效率而使用纹理缓存。实际使用时,必要数据每行大概5K,而一个452x52图像,对应的纹理缓存中像素就要占用94016字节(452x52x4),即一个452x52的图像数据就抵上18行。
虽然必要数据相比非必要部分是要少很多,但会一直占用内存,还是希望尽可能减少,尤其是所有控件的基类twidget。至于如何节省,就要涉及到C/C++语法,像少用std::string。
这里采用第二种方案,垃垃回收时回收的是行中的非必要数据。
二、步骤:分配、回收
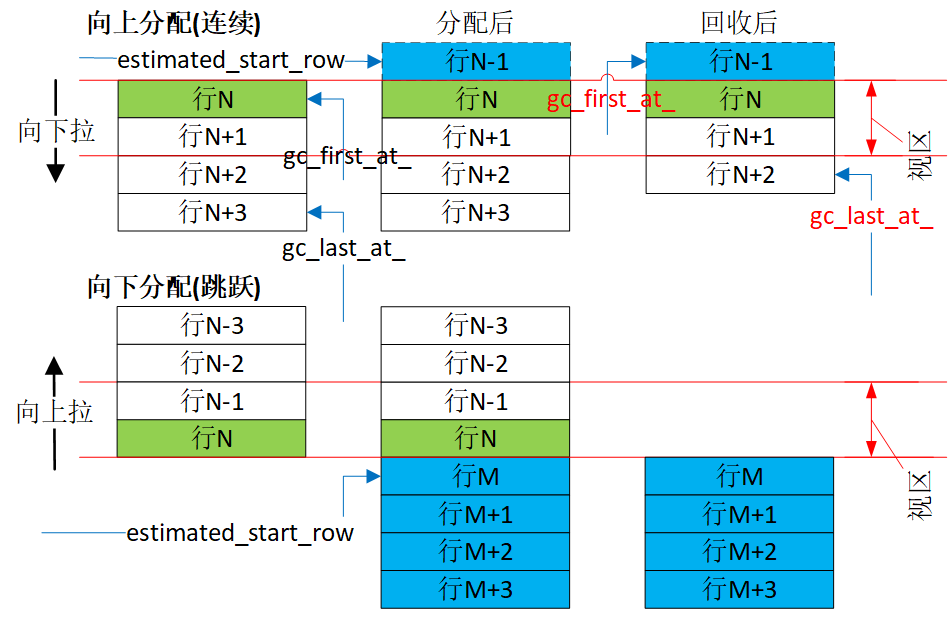
对图中的“向上分配(连续)”,最小的操作行N已显示在视区顶部,但用户继续小幅度向下拉动列表,程序表现上是小幅减少视区偏移。算法首先估算此次分配要从哪行开始,即算出estimated_start_row。算法规定:在像素上,新分配是从item_position_上面的content_->h/2处开始,start_distance = item_position_ - content_->h_/2。经过像素到行转换,算出estimated_start_row是N-1,并从它开始算累计行高valid_height。算法规定:累计行高一直要让超过2倍视区。N-1、N、N+1、N+2后,valid_height有2倍视区了,分配阶段结束,进入回收。回收阶段是销毁此次分配不涉及到的原操作区行中的非必要数据,即N+3。于是经过分配、回收后,操作区依旧保持着原先的4行。
对图中的“向下分配(跳跃)”,最大的操作行N已显示在视区底部,但用户继续大幅度向上拉动列表,程序表现上是大幅增加视区偏移。算法首先估算此次分配要从哪行开始,即算出estimated_start_row。算法规定:在像素上,新分配是从item_position_上面的content_->h/2处开始。经过像素到行转换,从start_distance算出estimated_start_row是M,并从它开始算累计行高valid_height。算法规定:累计行高一直要让超过2倍视区。M、M+1、M+2、M+3后,valid_height有2倍视区了,分配阶段结束,进入回收。回收阶段是销毁此次分配不涉及到的原操作区行中的非必要数据,即N-3、N-2、N-1、N。于是经过分配、回收后,操作区依旧保持着原先的4行。
不论向上还是向下分配,逻辑是一样的。
- 算出要此次操作区要从哪行开始,记为estimated_start_row。算法规定:在像素上,新分配是从item_position_上面的content_->h/2处开始。
- 从estimated_start_row起,累加该行及后续行高度。算法规定:累计行高一直要让超过2倍视区。一旦高度到达2倍的content_->h,分配结束。
- 回收此次分配不涉及的原操作区中行的非必要数据。
对等行高的列表,连续分配一次最小增加content_->h_/4,最大content_->h*3/4,跳跃分配则2*content_->h。
三、数据结构:ttoggle_panel
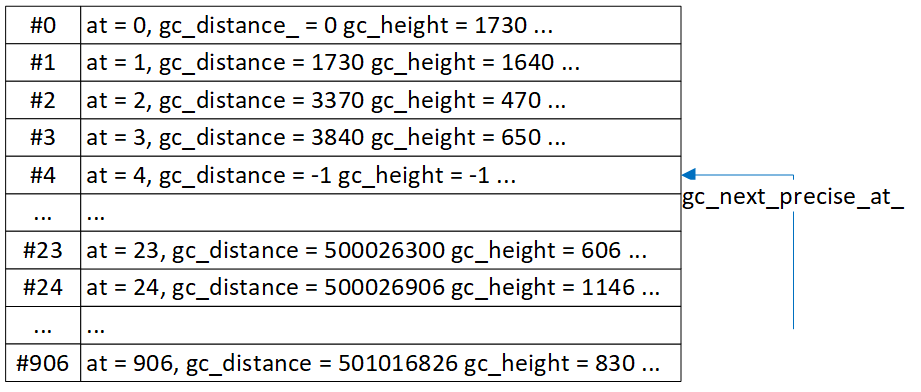
distance指示垂直方向上、该行在列表的偏移。数值上有三种格式。第一种是“-1”,它是初始值,表示该行从没出现在操作区。第二种小于500000000,该行出现过操作区,而且distance是一个精确值。第三种大于500000000,该行出现过操作区了,但distance是一个估计值。500000000是个主观定义的值,认为不可能有列表的高度超过这个值。
gc_height指示该行高度。数值上有两种格式。第一种是“-1”,它是初始值,表示该行没出现过操作区。第二种是个正数,该行出现过操作区了,然后根据算出了真实高度。
让以“向下分配(跳跃)”为例,基于数据结构重看下算法。假设conteng_->h_=840,图中N对应“#3”。
操作区中最大行#3已显示在视区底部,但用户继续大幅度向上拉动列表,item_position_停在了26720。算法首先估算此次分配要从哪行开始,即算出estimated_start_row。算法规定,在像素上,新分配是从item_position_上的content_->h/2处开始,根据start_distance=item_position_ - content_->h/2,算出是26300。经过像素到行转换,从start_distance算出estimated_start_row是#23,于是从#23开始算累计行高valid_height。算法规定:累计行高一直要让超过2倍视区。#23(606)、#24(1146)后,valid_height有2倍视区了,分配阶段结束,进入回收。回收阶段是销毁那些此次分配不涉及到的操作区中行的非必要数据,即#0、#1、#2、#3。于是经过分配、回收后操作区只存在#23、#24两条行。
四、估算:列表高度、estimated_start_row
对成百上千行的列表,用户很容易就会移到前面存在没有创建过行的行,这时就不得不进行估算。估算至少要算两个变量:列表高度和estimated_start_row。
列表高度
int tlistbox::calculate_total_height_gc() const
{
if (gc_next_precise_at_ == 0) { return 0; }
const tgc_row* row = gc_rows_[gc_next_precise_at_ - 1].get();
const int precise_height = row->distance + row->height;
const int average_height = precise_height / gc_next_precise_at_;
return precise_height + (gc_rows_.size() - gc_next_precise_at_) * average_height;
}以上是估算列表高度代码。高度分两部分,前面是精确行的高度(precise_height),后面是以平均行高(average_height)计算出的高度。gc_next_precise_at_是两类行的分隔点,它总是指向第一条没被精确计算过distance的行。它会随着列表中更多行被看过而不断变大。在图3,假设#4被看过了,那gc_next_precise_at_就会变大,一旦gc_next_precise_at_大到等于整个列表的行数,意味着整个列表都被用户看过了。
代码一开始总会把#0放入操作区。这意味着,在回收算法时gc_next_precise_at_总是大于0,precise_height也总是大于0,于是用它们总能算出average_height。当然,这个行高是根据已有的精确行算出的,可能不等于整个列表的真实行高,甚至可能相差很大。
计算行高要注意,虽然是估算,但需要是精确可逆。可逆指如果以行数R算出的像素数高度是P,那以P反向算出的必须是R。估算estimated_start_row时需要这个条件。
estimated_start_row
estimated_start_row指示此次分配要从哪行开始,它计算自start_distance,start_distnace则来自于“item_position_ - content_->y / 2”。那如何由start_distance算出estimated_start_row?
- 搜索精确行,即start_distance是否属于[0, precise_height - 1]。它属于精确计算。
- 如果不在精确行,搜索操作区中的行。操作区中的行除了自个那些行范围外,还可向上、向下各扩展出一行,这两行的高度是平均行高。它属于估算。
- 如果以上都没有,则用以下公式估算。
estimated_start_row = gc_next_precise_at_ + (start_distance - precise_height) / average_height;
这个公式要求估算列表高度和估算estimated_start_row时的平均行高必须一致,这也意味着计算行高时必须精确可逆,否则由start_distance计算出的行会越界,导致不可预料结果。
五、不等高行的列表
算法存在一条和计算distance有关的规则:如果此次estimated_start_row是估算出来的,start_distance将作为操作区中第一行的distance,后续行基于它进行计算,之前如果有存在的distance,将被覆盖。出来这条规则的原因是,随着更多行被翻看,估算会越来越准,而之前有些行估算出的distance会证明是错的。
这规则会导致这样结果:对估算出的行,分配前后它的distance会出现变动。以图3中的#23为例,第N次时start_distance是26300,那分配后distance是26300。下一次start_distance是26400,估算estimated_start_row还是等于#23,这次分配后distance就变成26400,于是分配前后就造成100像素变动。这个变动会造成“小幅移动列表时会出现列表跳动”。解决方法是在操作区找出第一条分配前后都存在的行,称为较正行,算出它们的distance偏差,然后修正到item_position_。
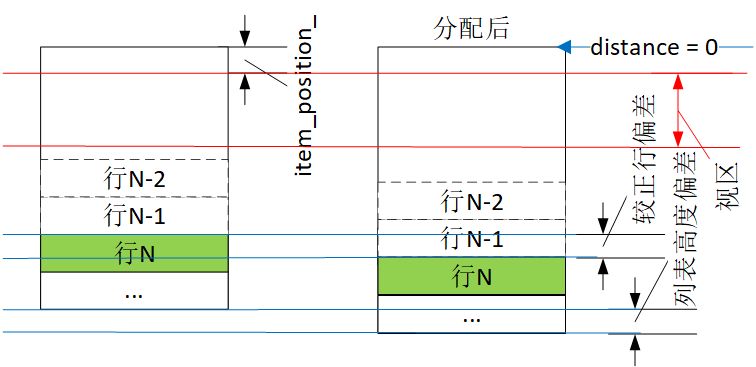
注:此个修正有可能造成item_postion_跳出操作区,从而导致界面错误。修正要求只是小幅移动,像慢慢向上/向下拉动列表。正因为有这潜在问题,列表的垃圾回收专门增加了个滚动到指定行的功能(gc_locked_at_!= npos),那时肯定不用较正行。
较正行修正法可小结为:分配前后不能改变item_position_位置,这个位置不是指数值,而是它指向的列表y位置。这时有人会问,跳跃分配没有较正行,那怎么办?——既然是跳跃,用户看到的列表内容本就会跳动,加个distance导致的跳动也没啥影响了。
除了较正行的distance偏差,不等高行还会造成一个问题是每次分配后的列表高度(height2)和height会有偏差。除了calculate_total_height_gc,计算列表高度还有以下方法。假设图3中操作区的最大行是#N,last_gc_row2指向#N。
const int average_height2 = precise_height / gc_next_precise_at_; height2 = distance_value(last_gc_row2->distance) + last_gc_row2->height; height2 += average_height2 * (rows - last_children_row->at_ - 1);
height2这个高度和以calculate_total_height_gc计算出的height往往会存在个偏差。由于窗口是把height作为此列表高度,此次分配的操作区中行为迎合height,它须要用这个偏差修正distance,即所有行的distance要减去“height2 - height”。同时,item_position_也要减去这偏差。
换句话说,不论什么时候,窗口知道的content_grid_->h_等于calculate_total_height_gc,即item_position_(窗口计算)范围是[0, height - 1]。这个范围要能应用到列表内部,那么列表内部算出的distance必须为迎合height进行修正,即“height2 - height”。
可能要对item_position_进行两次修正,一是基于较正行,二是基于“height2 - height”。
在修正的行中,要确保不出现“gc_distance_ < 0”。也就说,对估计行,必须满足gc_is_estimated(gc_distance_)。
六、tlistbox::scroll_to_row
void tlistbox::scroll_to_row(int at)
{
..,
if (need_layout_) {
return;
}
...
}在launcher的“中心”窗口,聊天日志history_是个tlistbox控件。它位于一个tstack,这个tstask有两个layer,一个是history_所在的HOME_LAYER,一个是显示相机实时图像的CAMERA_LAYER。当前正显示CAMERA_LAYER时,因为HOME_LAYER不处于VISIBLE,即使调用gui2::absolute_draw,也不会重新layout_children这个history_。要是在这种情况下(当前正显示CAMERA_LAYER时),history_.clear()后,调用gui2::absolute_draw,然后执行“认为”垃圾相关变量有效的操作,像tlistbox.scroll_to_row(at),那会导致出问题。
need_layout_==true,意味着此时垃圾收集相关变量可能是无效的,像gc_first_at、gc_last_at_值还是nposm,造成原因,可能刚调用过clear()。为让这些变量有效,需要执行一次tscroll_container::place()。在scroll_to_row则只能啥也不做。