
- 出错时,恢复性操作是从0开始,还是从上一次执行后的recovery_index_开始?遵循这么条规则:如果执行恢复性操作后,能够把之前导致出错的原因解决掉,下次就从0开始,否则从上一次执行后的recovery_index_开始。
一、状态和出错原因
1.1 状态
move_base节点有3种状态:PLANNING、CONTROLLING和CLEARING。一旦初始化后,过程中会执行的就是收到sendGoal时的executeCB,总是在导航中。
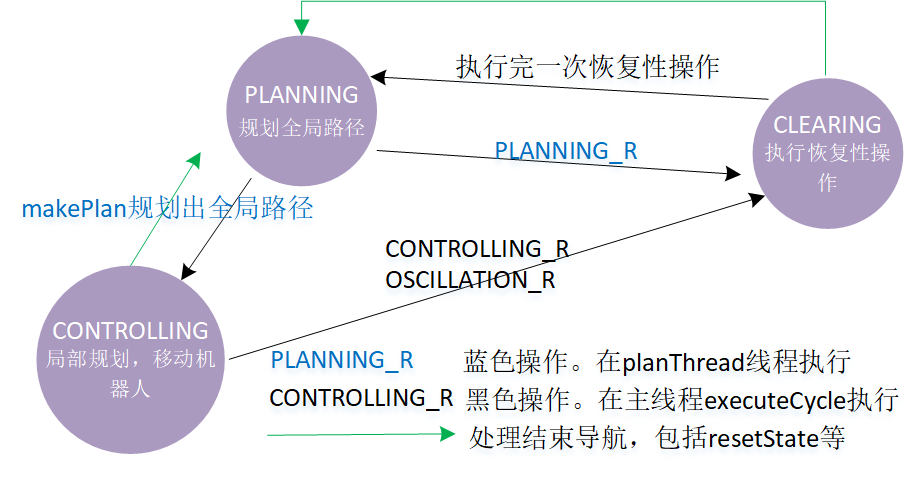
- PLANNING。该阶段要调用makePlan规划全局路径。规划出路径后进入CONTROLLING。如果长时间规划失败,进入CLEARING(PLANNING_R)。
- CONTROLLING。已获得了全局路径,一次又一次进行着局部规划,根据得出的速度移动机器人,直到到达goal。如果出现长时间局部规划失败(CONTROLLING_R),或长时间机器人不动(OSCILLATION_R),进入CLEARING。
- CLEARING。导航卡住了,试着执行恢复性操作。操作执行完后转入PLANNING。
看下导航过程没发生问题时的状态变换。
- (主线程)接收到sendGoal请求,状态进入PLANNING。
- (planThread)执行makePlan规划全局路径。规划出路径后,状态进入CONTROLLING
- (主线程)局部代价地图算出一个最优cmd_vel,按这速度移动机器人。
- (主线程)稍做等待,用tc_->isGoalReached判断是否到goal,如果没有,转到步骤3。如果到达了,此次导航结束。
如果一切正常,不会进入CLEARING,要进入CLEARING是导航出问题了,要进行容错处理。简单来说,机器人在哪里卡住了,要根据经验试着让机器人N种恢复性操作。这N种操作不是每次出错就全做,而是只做一种。举个例子,第一次出错时,做第一种恢复操作;第二次出错时,做第二种恢复操作,如果N种做完了依旧失败,那只能中止导航。每做完一种恢复性操作后,状态一律进入PLANNING。
1.2 出错原因
move_base把出错原因归为三种:PLANNING_R、CONTROLLING_R和OSCILLATION_R,下表是这三种原因各自涉及到的设置参数。
| 参数 | 原因 | 目前值 | 描述 |
| planner_patience_ | PLANNING_R | 2(秒)[注1] | 一旦累计已花在全局路径规划时间超过3秒,进入CLEARING状态 |
| max_planning_retries_ | PLANNING_R | -1(次)[注2] | 一旦全局路径规划失败次数超过uint32_t(-1)次,进入CLEARING状态。 |
| controller_patience_ | CONTROLLING_R | 3.0(秒) | 一旦累计已花在局部规划时间超过3秒,进入CLEARING状态 |
| oscillation_distance_ | OSCILLATION_R | 0.2(米) | 两次位置差值>=20厘米,认为机器人出现了不是抖动的移动 |
| oscillation_timeout_ | OSCILLATION_R | 10.0(秒) | 一旦机器人已有超过10秒没动过,进入CLEARING状态 |
- 注1:一旦全局路径规划失败,在短时间内,很少能变成成功。当然有这么种可能,起点和目标点之间存在走来走去的人,恰好走开关键位置了,使变得成功。结合恢复性操作trose_recovery,那里会把代价地图设为默认值,能缓解这情况。为减少溢出时间,有些厂家是5秒,这里降到2秒。
- 注2:由于uint32_t(-1)是个极大值,现实中不会出现超过这么多的失败次数,即目前对全局路径规划失败导致的中止只考虑时间因素。
执行完所有恢复性操作后,还是不行,要结束此次导航。不论什么原因,result是“因失败而中止:setAborted”。
PLANNING_R:一直规划不出全局路径
- last_valid_plan_记为最近一次规划出全局路径时刻。
- (planThread)此次makePlan规划全局路径的失败。
- (planThread)累计已花在规划全局路径时间是否超过5秒,如果没有,转到步骤1,继续规划。否则进入CLEARING状态。recovery_trigger_ = PLANNING_R。
CONTROLLING_R:全局路径是规划出来了,但规划本地路径失败
想像机器人处在这么个空间,它到goal可以有数条路径,有很很窄的路径a到gobal最短,于是全局规划时选了这条路径,因为全局规划时不考虑机器人足迹。但由于这路很窄,一到局部代价地图,考虑机器人足迹后,本地规划的失败。
- last_valid_control_记为最近一次规划出本地路径时刻。
- (主线程)tc_->computeVelocityCommands(cmd_vel),执行本地规划,失败。
- (主线程)判断本地规划累计失败时长是否>=controller_patience_秒,如果没有,进入步骤4。否则进入步骤5。
- (主线程)进入PLANNING状态,再次执行全局路径规划。规划出一条全局路径后,进入步骤2。
- (主线程)超过controller_patience_秒,本地规划都是失败,进入CLEARING状态。recovery_trigger_ = CONTROLLING_R。
OSCILLATION_R:机器人在来回摆动,长时间被困在一小片区域,包括就是不动,像轮子坏了
move_base认为,如果两次位置差值<oscillation_distance_,那就是没有移动。目前oscillation_distance_取值是0.2,即20厘米。
- last_oscillation_reset_记为最近一次机器人有过移动的时刻。
- (主线程)每次executeCycle时间片,检查机器人是否发生了移动。
- (主线程)累计已超过oscillation_timeout_秒都没有移动吗?如果没有,啥也不做。否则进入CLEARING状态。recovery_trigger_ = OSCILLATION_R。
1.3 planThread
planThread是planThread线程的处理例程。
void trose_slice::planThread(bool& exit)
{
ROS_DEBUG_NAMED("move_base_plan_thread","Starting planner thread...");
// ros::NodeHandle n;
// n.setCallbackQueue(&cbqueue_);
ros::Timer timer;
while (!exit) {
// check if we should run the planner (the mutex is locked)
if (!runPlanner_) {
SDL_Delay(10);
continue;
}
if (exit) {
break;
}
ros::Time start_time = ros::Time::now();
geometry_msgs::PoseStamped temp_goal;
{
threading::lock lock(planner_mutex_);
// time to plan! get a copy of the goal and unlock the mutex
temp_goal = planner_goal_;
}
ROS_DEBUG_NAMED("move_base_plan_thread","Planning...");
//run planner
planner_plan_->clear();
bool gotPlan = makePlan(temp_goal, *planner_plan_);
if (gotPlan) {
ROS_DEBUG_NAMED("move_base_plan_thread","Got Plan with %zu points!", planner_plan_->size());
//pointer swap the plans under mutex (the controller will pull from latest_plan_)
std::vector<geometry_msgs::PoseStamped>* temp_plan = planner_plan_;
threading::lock lock(planner_mutex_);
planner_plan_ = latest_plan_;
latest_plan_ = temp_plan;
last_valid_plan_ = ros::Time::now();
planning_retries_ = 0;
new_global_plan_ = true;{PLANNING_R[1/3]}此次规划全局路径成功,last_valid_plan_记住这个时刻。
ROS_DEBUG_NAMED("move_base_plan_thread","Generated a plan from the base_global_planner");
// make sure we only start the controller if we still haven't reached the goal
if (runPlanner_) {
state_ = CONTROLLING;
}
runPlanner_ = false;
}
// if we didn't get a plan and we are in the planning state (the robot isn't moving)
else if (state_ == PLANNING) {{PLANNING_R[2/3]}此次规划全局路径失败。
ROS_DEBUG_NAMED("move_base_plan_thread","No Plan...");
ros::Time attempt_end = last_valid_plan_ + ros::Duration(planner_patience_);
//check if we've tried to make a plan for over our time limit or our maximum number of retries
//issue #496: we stop planning when one of the conditions is true, but if max_planning_retries_
//is negative (the default), it is just ignored and we have the same behavior as ever
threading::lock lock(planner_mutex_);
planning_retries_++;
if (runPlanner_ &&
(ros::Time::now() > attempt_end || planning_retries_ > uint32_t(max_planning_retries_))){
//we'll move into our obstacle clearing mode
state_ = CLEARING;
runPlanner_ = false; // proper solution for issue #523
publishZeroVelocity();
recovery_trigger_ = PLANNING_R;{PLANNING_R[3/3]}累计失败次数或时长溢出。
规划全局路径失败,是否要进入CLEARING,取决于是否满足两个条件中一个。
- 根据last_valid_plan_判断累计已花在规划全局路径时间,一旦超过planner_patience_(5秒),进入CLEARING。
- 判断累计已规划全局路径失败次数planning_retries_,如果超过max_planning_retries_,进入CLEARING。
在目前设置中planner_patience_=5,planning_retries_= -1,由于-1转到uin32_t就是最大值,不可能满足这条件,是否进入CLEARING,只取消决于累计已花在规划全局路径时间是否超过5秒。
} } } }
1.4 executeCycle
executeCycle是个时间片函数。对move_base,每隔(1.0/controller_frequency_)秒会执行一次。对它的返回值,true表示此次executeCycle结束了此次导航,结果可能是成功,可能失败。
bool trose_slice::executeCycle(const geometry_msgs::PoseStamped& goal)
{
// boost::recursive_mutex::scoped_lock ecl(configuration_mutex_);
//we need to be able to publish velocity commands
geometry_msgs::Twist cmd_vel;
//update feedback to correspond to our curent position
geometry_msgs::PoseStamped global_pose;
planner_costmap_ros_->getRobotPose(global_pose);
const geometry_msgs::PoseStamped& current_position = global_pose;
// push the feedback out
// move_base_msgs::MoveBaseFeedback feedback;
// feedback.base_position = current_position;
// as_->publishFeedback(feedback);
//check to see if we've moved far enough to reset our oscillation timeout
if (distance(current_position, oscillation_pose_) >= oscillation_distance_) {
last_oscillation_reset_ = ros::Time::now();
oscillation_pose_ = current_position;{OSCILLATION_R[1/3]}此次检查发现机器人有过移动,last_oscillation_reset_记住这个时刻。
//if our last recovery was caused by oscillation, we want to reset the recovery index
if (recovery_trigger_ == OSCILLATION_R) {
recovery_index_ = 0;
}
}
//check that the observation buffers for the costmap are current, we don't want to drive blind
if (!controller_costmap_ros_->isCurrent()){
publishZeroVelocity();
return false;
}
// if we have a new plan then grab it and give it to the controller
if (new_global_plan_) {
//make sure to set the new plan flag to false
new_global_plan_ = false;
ROS_DEBUG_NAMED("move_base","Got a new plan...swap pointers");
//do a pointer swap under mutex
std::vector<geometry_msgs::PoseStamped>* temp_plan = controller_plan_;
{
threading::lock lock(planner_mutex_);
controller_plan_ = latest_plan_;
latest_plan_ = temp_plan;
}
ROS_DEBUG_NAMED("move_base","pointers swapped!");planThread成功规划出一条全局路径。把这全局路径改存到主线程能自由使用的controller_plan_。
if (!tc_->setPlan(*controller_plan_)) {
// ABORT and SHUTDOWN COSTMAPS
ROS_ERROR("Failed to pass global plan to the controller, aborting.");
resetState();
{
//disable the planner thread
threading::lock lock(planner_mutex_);
runPlanner_ = false;
}这里为什么会失败?
这里发生的错误认为是无法拯救,结束此次导航,result是结束之二“因失败而中止:setAborted”。
as_setAborted("Failed to pass global plan to the controller.");
return true;
}
//make sure to reset recovery_index_ since we were able to find a valid plan
if (recovery_trigger_ == PLANNING_R) {
recovery_index_ = 0;
}
}
//the move_base state machine, handles the control logic for navigation
switch (state_) {
// if we are in a planning state, then we'll attempt to make a plan
case PLANNING:
{
threading::lock lock(planner_mutex_);
runPlanner_ = true;
// planner_cond_.notify_one();
}
ROS_DEBUG_NAMED("move_base","Waiting for plan, in the planning state.");
break;
//if we're controlling, we'll attempt to find valid velocity commands
case CONTROLLING:
ROS_DEBUG_NAMED("move_base","In controlling state.");
//check to see if we've reached our goal
if(tc_->isGoalReached()){
ROS_DEBUG_NAMED("move_base","Goal reached!");
resetState();
{
//disable the planner thread
threading::lock lock(planner_mutex_);
runPlanner_ = false;
}
as_setSucceeded("Goal reached.");
return true;
}
//check for an oscillation condition
if (oscillation_timeout_ > 0.0 &&
last_oscillation_reset_ + ros::Duration(oscillation_timeout_) < ros::Time::now())
{
SDL_Log("%u, {leagor-verbose}check for an oscillation condition", SDL_GetTicks());
publishZeroVelocity();
state_ = CLEARING;
recovery_trigger_ = OSCILLATION_R;{OSCILLATION_R[3/3]}超过oscillation_timeout_秒都没有移动,进入CLEARING状态。。
}
{
boost::unique_lock<costmap_2d::Costmap2D::mutex_t> lock(*(controller_costmap_ros_->getCostmap()->getMutex()));
if (tc_->computeVelocityCommands(cmd_vel)) {{CONTROLLING_R[1/5]}此次在功规划出本地路径,last_valid_control_记住这个时刻。
ROS_DEBUG_NAMED( "move_base", "Got a valid command from the local planner: %.3lf, %.3lf, %.3lf",
cmd_vel.linear.x, cmd_vel.linear.y, cmd_vel.angular.z );
last_valid_control_ = ros::Time::now();
//make sure that we send the velocity command to the base
vel_pub_.publish(cmd_vel);
if (recovery_trigger_ == CONTROLLING_R) {
recovery_index_ = 0;
}
} else {{CONTROLLING_R[2/5]}执行本地规划,失败。
ROS_DEBUG_NAMED("move_base", "The local planner could not find a valid plan.");
ros::Time attempt_end = last_valid_control_ + ros::Duration(controller_patience_);
//check if we've tried to find a valid control for longer than our time limit
if (ros::Time::now() > attempt_end) {{CONTROLLING_R[5/5]}本地规划失败累计时长超过controller_patience_秒,进入CLEARING状态。
//we'll move into our obstacle clearing mode
publishZeroVelocity();
state_ = CLEARING;
recovery_trigger_ = CONTROLLING_R;
} else{{CONTROLLING_R[4/5]}本地规划失败累计时长<=controller_patience_秒。进入PLANNING状态,再次让执行全局路径规划。
//otherwise, if we can't find a valid control, we'll go back to planning
last_valid_plan_ = ros::Time::now();
planning_retries_ = 0;
state_ = PLANNING;
publishZeroVelocity();
{
threading::lock lock(planner_mutex_);
runPlanner_ = true;
// planner_cond_.notify_one();
}
}
}
}
break;
//we'll try to clear out space with any user-provided recovery behaviors
case CLEARING:
ROS_DEBUG_NAMED("move_base","In clearing/recovery state");
//we'll invoke whatever recovery behavior we're currently on if they're enabled
if (recovery_behavior_enabled_ && recovery_index_ < recovery_behaviors_.size()){
move_base_msgs::RecoveryStatus msg;
msg.pose_stamped = current_position;
msg.current_recovery_number = recovery_index_;
msg.total_number_of_recoveries = recovery_behaviors_.size();
msg.recovery_behavior_name = recovery_behavior_names_[recovery_index_];
recovery_status_pub_.publish(msg);
recovery_behaviors_[recovery_index_]->runBehavior();
//we at least want to give the robot some time to stop oscillating after executing the behavior
last_oscillation_reset_ = ros::Time::now();
//we'll check if the recovery behavior actually worked
ROS_DEBUG_NAMED("move_base_recovery","Going back to planning state");
last_valid_plan_ = ros::Time::now();
planning_retries_ = 0;
state_ = PLANNING;尝试第recovery_index_种恢复性操作。无论执行那种恢复性操作,状态都进入PLANNING。
{PLANNING_R[1/3]}已做了恢复性操作,让此刻成为累计多久没成功规划全局路径时刻,last_valid_plan_记住这个时刻,
//update the index of the next recovery behavior that we'll try
recovery_index_++;
} else {
做了所有恢复性操作后,仍旧失败。结束此次导航,result是结束之二“因失败而中止:setAborted”。
{
threading::lock lock(planner_mutex_);
//disable the planner thread
runPlanner_ = false;
}
ROS_DEBUG_NAMED("move_base_recovery","Something should abort after this.");
if(recovery_trigger_ == CONTROLLING_R){
as_setAborted("Failed to find a valid control. Even after executing recovery behaviors.");
}
else if(recovery_trigger_ == PLANNING_R){
ROS_ERROR("Aborting because a valid plan could not be found. Even after executing all recovery behaviors");
as_setAborted("Failed to find a valid plan. Even after executing recovery behaviors.");
}
else if(recovery_trigger_ == OSCILLATION_R){
as_setAborted("Robot is oscillating. Even after executing recovery behaviors.");
}
resetState();
return true;
}
break;
default:程序就不应该让进入这里。
ROS_ERROR("This case should never be reached, something is wrong, aborting");
resetState();
{
threading::lock lock(planner_mutex_);
//disable the planner thread
runPlanner_ = false;
}
as_setAborted("Reached a case that should not be hit in move_base. This is a bug, please report it.");
return true;
}
// we aren't done yet
return false;
}
二、三个全局路径:planner_plan_、latest_plan_、controller_plan_
std::vector<geometry_msgs::PoseStamped>* planner_plan_; std::vector<geometry_msgs::PoseStamped>* latest_plan_; std::vector<geometry_msgs::PoseStamped>* controller_plan_;
planner_plan_、latest_plan_、controller_plan_都用存储全局路径。为什么用指针,而不是std::vector对象?——过程中要对它们互换赋值,像planner_plan_和latest_plan_互换,用指针可以节省内存、cpu。它们生命期是和MoveBase对象一样。
在大致次序上,makePlan得到的结果赋给planner_plan_,但立即就赋给latest_plan_,latest_plan_则给了planner_plan_(我认主这个赋值可以省略)。“plan”topic发布的是makePlan得到的planner_plan_,但由于很快给了latest_plan_,可直观认为对应的是latst_plan_。在进入executeCycle时,再latest_plan_互换controller_plan_,最后进入BaseLocalPlanner的是controller_plan_。
latest_plan_表示上一次全局规划(makePkan)时规划出的路径。功能是用于同步。在planThread线程执行的makePlan需要点时间,过程中要一直接占用planner_plan_,要是主线程也要读planner_plan_的话,不方便线程同步。
- (planThread线程)调用makePlan规划路径,结果存放在planner_plan_。
- (planThread线程)获取路径锁(planner_mutex_),把planner_plan_赋值给latest_plan_,并把new_global_plan_设为true。释放路径锁,
- (主线程)发现new_global_plan_是true。获取路径锁,new_global_plan_设为false,把latest_plan_赋给值controller_plan_,释放路径锁。
有了latest_plan_后,planThread线程可自由使用planner_plan_,主线程可自由使用controller_plan_,controller_plan_就最近一次makePlan规划出的全局路径。
三、处理结束导航
结束导航包括两个操作,一是执行resetState(),二是向result话题发布此次导航结果。
resetState做下面操作。
- runPlanner_ = false。命令规划线程不再执行规划任务。
- 把一些变量复位到初始值。当中一个是状态恢复到PLANNING。
- 向机器人发布速度0,让机器人停下不动。
向result话题发布此次导航结果,状态码有三类。
result#1:导航成功(setSucceeded)
机器人成功移动到goal。
result#2:因失败而中止(setAborted)
哪里卡住了,尝试恢复后也没解决,只好中止,导航失败。
result#3:取消(setPreempted)
这指的是client发送了cancelGoal命令。
在move_base,当client发送了cancelGoal时,它进入的相关代码。
if (as_->isPreemptRequested()) {
// 这段代码位在executeCb,在as_认为,上一次的sendGoal还没处理完。这次又来cancelGoal/sendGoal,认为是取代(Preempt)。
if (as_->isNewGoalAvailable()) {
// sendGoal进入这里
} else {
// cancelGoal进入这里
as_->setPreempted();
}
四、恢复性操作
多个恢复性操作被组织成一个数组recovery_behaviors_,从索引0开始,不断被执行。如果所有恢复性操作执行完了,仍旧出错,那此次导航失败。recovery_index_对应着这个数级的索引,用于指示一旦要发生恢复性操作,要执行的第几个。
这有个问题,下次出错时,恢复性操作是从0开始,还是从上一次执行后的recovery_index_开始?——两个都有可能。遵循这么条规则:如果执行恢复性操作后,能够把之前导致出错的原因解决掉,下次就从0开始,否则从上一次执行后的recovery_index_开始。举个例子,recovery_index_正等于1,这次出错原因是CONTROLLING_R,也就是机器人来回摆动。如果执行recovery_index_[1]这个恢复性操作后,机器人成功移出一段距离,不来回摆动了,下次再执行恢复性操作时,recovery_index_将从0开始,否则将从2开始(上次执行恢复性操作后,recovery_index_被+1到2)。
五、MoveBase析构函数
析构MoveBase时,须注意销毁内中对象次序。个人认为官方~MoveBase是有问题的,当正处于恢复性操作RotateRecovery时,极可能导致程序崩溃。
MoveBase::~MoveBase(){
// 1. make sure exit executeCb and don't execute it again.
recovery_index_ = (int)recovery_behaviors_.size();
planner_patience_ = 0.0;
if (as_ != NULL) {
delete as_;
}
recovery_behaviors_.clear();首先要保证退出executeCB,并保证不会再被执行。
- recovery_index_ = (int)recovery_behaviors_.size()。recovery_behaviors_中存储着要依次执行的恢复性操作,极可能是多个操作,只有这些操作都被执行了,executeCb才会认为导航需要中止。这个赋值保证了,executeCb执行完正在运行的恢复性操作后,只要再次进入CLEARING,就中止导航。
- planner_patience_ = 0.0。如果executeCb当前正在执行恢复性操作,那完成这个操作后,便会让状态进入PLANNING。这个从5到0的修改让planThread线程只要一次makePlan失败,就进入CLEARING,不必等以往的5秒溢出。这里不去改max_planning_retries_,是考虑到一般不会用makePlan失败次数作为进入CLEARING条件。另外,也不是runPlanner_ = false,是因为如果当前正在执行恢复性操作的话,完成后,executeCb会把runPlanner_ = true,那上面修改就没用。
- delete as_。executeCB是在as_内部的ActionServerThread线程执行。销毁它,保证executeCB不会被调用。
- recovery_behaviors_.clear()。销毁要使用的恢复性操作对象,清空recovery_behaviors_。
// 2. dynamic_reconfigure::Server delete dsrv_;
dsrv_类型是dynamic_reconfigure::Server,我对动态配置了解不多。放这里是因为官方~MoveBase也是较早销毁它。
// 3. destroy planThread. // planThread use planner_costmap_ros_ during makePlan. delete planner_thread_;
销毁planThread线程。如果planThread正在执行makePlan,那要使用planner_costmap_ros_。所以必须放在销毁planner_costmap_ros_之前。
// 4. destroy gloal-costmap and local-costmap
if (planner_costmap_ros_ != NULL) {
delete planner_costmap_ros_;
}
if (controller_costmap_ros_ != NULL) {
delete controller_costmap_ros_;
}executeCB已不会执行,planThread已销毁,可安全销毁两个代价地图了。
// 5. misc object delete planner_plan_; delete latest_plan_; delete controller_plan_; planner_.reset(); tc_.reset(); }
至于~MoveBase要执行多少时间。最坏情况正在执行恢复性操作RotateRecovery,恰好又是开始的话,得等5秒溢出,这时时间5秒多点。对其它情况,时间应该很短。