
- zip包存储着四种数据:概述、unicode到拼音索引的数组、拼音索引、wav数据。
- 宏MAX_PINYIN_BYTES指示一个拼音最大字节数,值是7,像chuang2。
- 汉字存在多音字。宏RSP_PINYINS_PER_WORD指示一个汉字可拥有的最多拼音数,值是4。一个汉字最多支持4个拼音。
- 结构trsp_pinyinindex表示一个拼音索引,每个索引字节数是sizeof(trsp_pinyinindex)。在概述区,pinyins字段指示了rsp文件中有效的拼音数,的确,拼音索引区的一个索引表示一个拼音,但索引区的拼音数可能超过pingyins。所以不能由pingyins*sizeof(trsp_pinyinindex)得到wav数据的起始偏移,而是应该由概述的wav_start得到这个偏移。
为直观,本文用一个示例来描述拼音rsp。
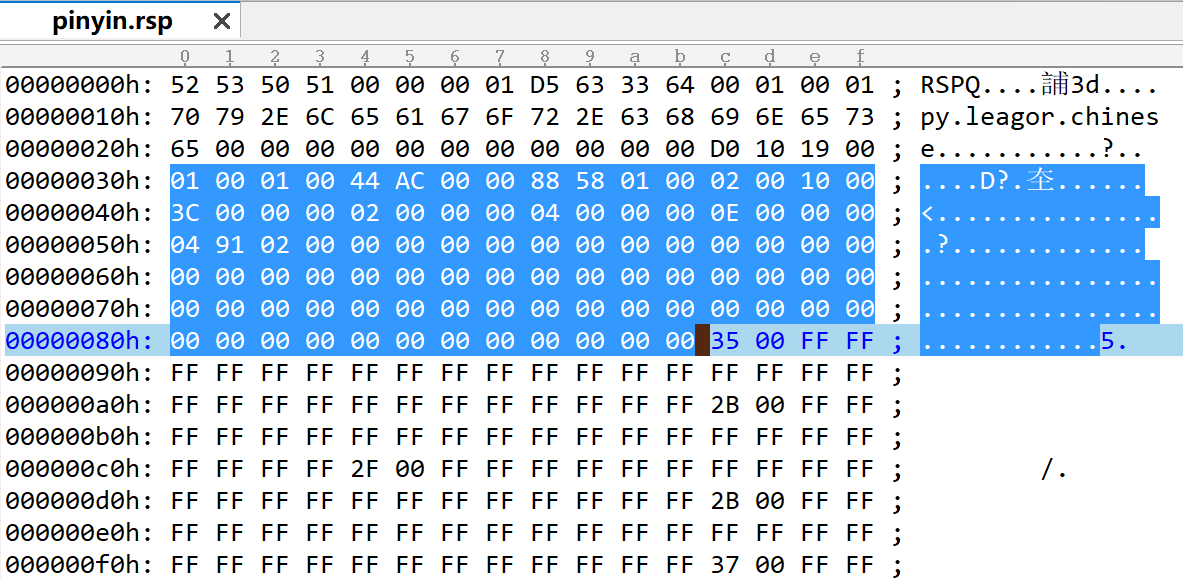
图1中高亮部分是92字节的trsp_pinyin92bytes。
一、第一部分:rsp头(48字节)
Tag3-H4=5(zipt_pinyin)
zip包中数据版本:0.0.1-1681023058(0x64326052)。0.0.1是zip包中版本格式,可认为是拼音的存储格式版本。目前是0.0.1。1681023058是此拼音包的最后修改时间,用C函数time(nullptr)生成。
rose版本:1.0.1。
bundleid:py.leagor.chinese。对拼音,bundleid的第一段建议用“py”。
zip包字节数:0x1910d0 = 1,642,704。可算出该rsp文件字节数:48 + 1,642,704 + 20 = 1642772。而1,642,704由四部分组成。
| 次序 | 内容 | 字节数 | 描述 |
| #1 | 概述 | 92 | 固定字节数。sizeof(trsp_pinyin92bytes) |
| #2 | unicode到拼音索引映射 | 167216 | 固定字节数。get_pinyin_code_bytes() * 2 * RSP_PINYINS_PER_WORD(4) |
| #3 | 拼音索引 | 840 | 可变字节数。wavs.size() * bytes_per_index(14) |
| #4 | wav数据 | 1474556 | 可变字节数。拼音rsp的主要部分 |
二、zip包
2.1 概述
概述存储着拼音描述信息,它是一个trsp_pinyin92bytes结构。
struct twave_format_16bytes {
uint16_t encoding; // Actual encoding, possibly from the extensible header.
uint16_t channels; // Number of channels.
uint32_t frequency; // Sampling rate in Hz.
uint32_t byterate; // Average bytes per second.
uint16_t blockalign; // Bytes per block.
uint16_t bitspersample; // Currently supported are 8, 16, 24, 32, and 4 for ADPCM.
};
#define RSP_MAXDESCBYTES 55
struct trsp_pinyin92bytes {
twave_format_16bytes format;
uint32_t pinyins;
uint32_t bytes_per_index_code;
uint32_t pinyins_per_word;
uint32_t bytes_per_index;
uint32_t wav_start;
char desc[RSP_MAXDESCBYTES + 1];
};针对示例,它从0x30开始,占92字节。
- format:描述声音存储格式。一般采用示例中的PCM、单声道、44.1K、S16位。
- pinyins:60(0x3c)。wav数据区存储着60个拼音。
- bytes_per_index_code:2。每个索引编码字节数。2个字节可表示65536个编码,除去0xffff表示无效编码,一个拼音rsp最多存储65535个拼音。
- pinyins_per_word:4(RSP_PINYINS_PER_WORD)。用于多音字,表示每个汉字最多含有的拼音数。一个汉字最多含4个拼音。
- bytes_per_inex:14。sizeof(trsp_pinyinindex)。索引区每个索引的字节数。
- wav_start:168196(0x00029104)。wav数据区开始位置。
- desc:用于描述该拼音使用场景的一个字符串。56字节。
2.2 unicode到拼音索引的数组
数组中每一项是一个trsp_pinyinunicode结构。
#define RSP_PINYIN_NO_INDEX_CODE 0xffff
#define RSP_PINYINS_PER_WORD 4
struct trsp_pinyinunicode {
uint16_t idxs[RSP_PINYINS_PER_WORD];
};数组索引表示unicode编码。拼音rsp存储的汉字从unicode编码从0x4E00开始,到0x9FA5结束。索引0对应的是汉字0x4E00,即“一”,索引1对应0x4E01,即“丁”。
数组值是该汉字在拼音索引区的索引编码。每个拼音索引编码2个字节,一个汉字固定4个拼音。当然,汉字很少会有4个拼音,不足4个的,就填0xFFFF,表示无效拼音。
以索引0为例,对应的是汉字0x4E00,即“一”,它有一个拼音,在拼音索引区的53(0x35)。
2.3 拼音索引
一个拼音索引描述一个拼音,除了声音wav数据。
#define MAX_PINYIN_BYTES 7 // chuang2
struct trsp_pinyinindex {
char pinyin[8]; // chuang2\0, must > MAX_PINYIN_BYTES.
int offset; // 0 is wav-data
int16_t size;
};- pyinyin:存储着该拼音内容。像chuang2。汉字拼音最多7个字符,加上一个C语言字符串终止符'\0',用8个字节。
- offset。该拼音在wav数据区的开始偏移。
- size。该拼音在wav数据区的字节数。
读取逻辑定位到offset处,从它开始读size字节,读出的便是该拼音的wav数据。
2.4 wav数据
各个拼音的wav数据。概述区中的format字段指示了当中声音数据格式。所有拼音必须有着一样的格式。