
代码参考:小程序Basic(aplt.leagor.basic)有一个语音驱动实例tleagor_speech。
视频1演示了新建小程序、让小程序符合语音驱动规范、使用poedit、小程序上传到商店、从商店下载内测版,这整个过程。
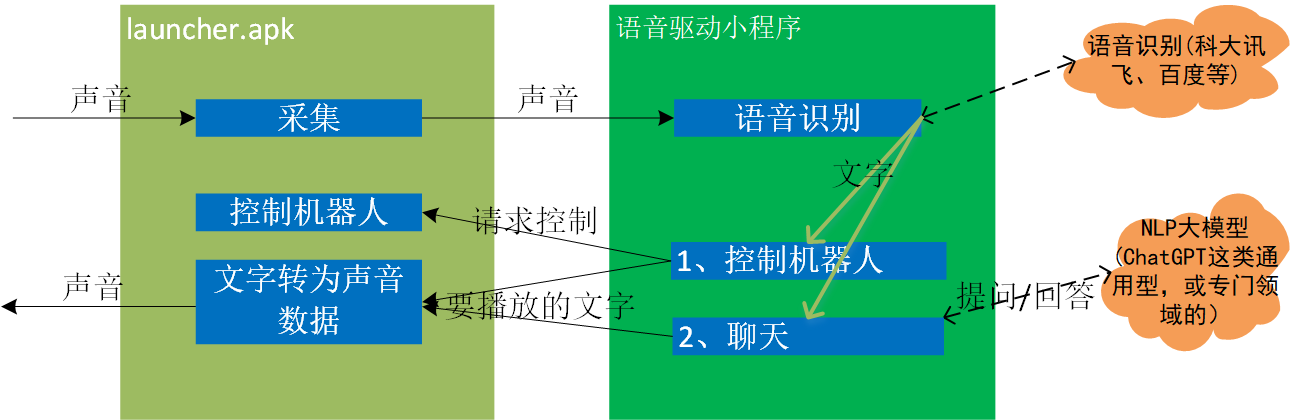
- 机器人采集到用户说的声音后,判断出来可能是段有效语音,就进行语音识别,得到一段文字。
- 解析文字,这段文字至少可能有两种功能,一是用于控制机器人,二是聊天。
- 用于控制机器人的文字。举个例子,命令机器人去启动豆浆机。机器人收到命令后,将移动到豆浆机,同时为让用户知道收到这命令了,会发出声音:“好的,这就去启动豆浆机”。
- 用于聊天的文字。举个例子:叫机器人背《静夜思》。这时是作为一个问题提交给NLP模型,NLP模型返回以文字表示的回答。接下把文字表示的回答转为声音,再叫机器人播放出来。于是现实人和机器人聊天。
正如上图所述,语音识别,识别出文字后怎么解析,怎么由文字表示的问题得到答案,这些都是语音驱动小程序实现。语音识别用的是科大讯飞还是百度,NLP模型用的是哪家,全看你此刻使用的是哪个语音驱动小程序。
一、输出规范
1.1 settings.cfg
speech_driver = yes
根下需存在键“speech_driver”,值是bool类型的“yes”。
1.2 libroseaplt.so需输出函数:aplt_create_speech_slot
void* aplt_create_speech_slot();
返回值是个指向aplt::tspeech_slot对象的指针。
二、识别、解析语音

语音驱动涉及三个线程:主线程,声音采集线程和语音识别线程。让根据图2,看一次语音处理过程。
- [采集线程]提取出一段认为是语音的声音片断,记为(data_, voice_len_)。
- [采集线程]将voice_event_设为有信号,唤醒识别线程。
- [识别线程]调用虚函数recognize()识别声音片断(data_, voice_len_),tleagor_speech用的是科大讯飞语音识别算法。识别出的文字放在函数内变量result。
- [识别线程]把result值安全地放在类内变量vocie_result_,让主线程可以访问。
- [主线程]在新近一次tleagor_speech::slice,发现voice_result_不是空,先安全地转放到函数内变量result。至此result存储着一段新近识别出的语音。根据文字内容可执行不同操作。
tspeech_slot::DoWork是声音识别线程默认执行的操作。如果不重载它,语音驱动须实现方法:has_voice、recognize。
在slice,安全得到一个非空的result后,便可根据不同内容执行不同操作。
2.1 控制机器人
执行一个aplt::treq_task封装的任务
| type | 描述 | 生成该任务的方法 |
| type_moveto | 移动到某个位置 | set_moveto |
| type_moveto_recognition | 移动到某个位置,移动成功后开始识别物体 | set_moveto_recognition |
| type_recognition | 原地开启摄像头,识别物体 | set_recognition |
得到任务treq_task后,以它为参数调用tros::request_task,便可让launcher去执行该任务。
要求机器人播放一段声音
aplt::tpinyin::speak,参数是utf-8格式的一个字符串。
三、提取声音片断送去语音识别
对语音驱动,一个工作是要从声音流中提取片断,送去语音识别。这里说下Basic内置的语音驱动是怎么个提取过程。
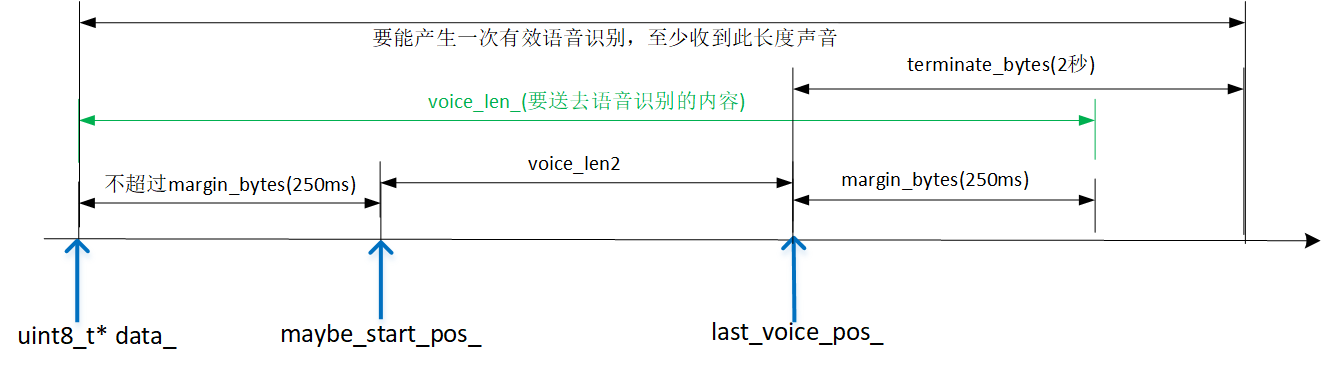
- int voice_threshold_。人声阈值(4000,运行时可修改)。当检测到有音量>=该值,认为有人说话了。将给maybe_start_pos_赋一个非nposm的值。
- int bytes_per_sec。一秒声音等价的字节数。对单声道、16000采样率、16位PCM,值是32000。
- int margin_bytes = bytes_per_sec / 4。250毫秒,人声前、后空白区。人说话时,不大可能一出声,音量就超过人声;同样的,要停止时,音量不大可能一下从超过人声就变0。为识别第一个和最后一个字,须要给人声前、后多送一段。
- const int terminate_bytes = bytes_per_sec * 2。当音量低于人声持续超过terminate_bytes,认为此轮人声应该是结束了。
- const int max_cached_silent_bytes = bytes_per_sec * 3。 如果持续3秒都没人声,扔弃前3秒。从3秒后重新开始。避免data_缓存尺寸过大。
- const int min_voice_len = 55 * bytes_per_sec / 100。550ms。说话长度至少要>=550毫秒。
- const int max_voice_len = 7 * bytes_per_sec。7秒。说话长度最长不能超过7秒。
- int maybe_start_pos_。人声在声音缓冲区(data_)的开始位置。nposm表示当前没检测到人声。
- int voice_len_。要送去语音识别的字节数。
- int last_voice_pos_。最后一个人声出现的位置。voice_len_ = last_voice_pos_ + margin_bytes;
当录到一段新声音,会调用tleagor_speech::did_capture_audio,在这函数提取人声。
- 如果还没检测到人声,并且缓存声音已超过3秒(max_cached_silent_bytes)。扔弃前3秒,从(3-margin_bytes)秒后重新开始。
- 逐个检查新收到样本,一旦该样本是人声。1)如果maybe_start_pos_是nposm,给maybe_start_pos_赋一个非nposm的值,同时变量start_found=true。2)赋值给last_voice_pos_。——至此,maybe_start_pos_指向缓冲区的第一个人声,last_voice_pos_指向缓冲区的最后一个人声。
- 新收到声音数据放入data_缓存。接下要根据当前状态分三种处理。
4.1)如果首次发现人声(start_found==true),确保maybe_start_pos_离起始不超过250毫秒(margin_bytes)。这是为了让送向识别的声音数据尽可能短,但人的说话不大可能第一个样本就是人声,于是前面会最多送250毫秒数据。
4.2)如果之前轮已发现人声(不是首次)。算出人声长度(voice_len2),即最后一个人声减去第一个人声。1)如果voice_len2超过max_voice_len(7秒),认为一次说得太长,复位相关变量,此次did_capture_audio结束。2)如果最后一个人声后超过3秒(terminate_bytes)没人声了,这时检查voice_len2是否小于550毫秒,一旦小于,认为这次说得太短,复位相关变量,此次did_capture_audio结束。否则算出voice_len_,把它送去语音识别。
4.3)这应该是到现在还没发现人声。此次did_capture_audio结束。
对声音内容,只需要第一个人声样本、最后一个人声样本,没有根据中间数据判断这段声音是否是人声,还只是音量超过人声音量的噪音。对送去识别的声音(voice_len_),可分为三段,第一段是第一个人声样本前的空白,最长不超过margin_bytes。第二段是第一个人声和最后一个人声之间的声音,这长度必须在范围[550毫秒, 7秒]。第三段是最后一个人声样本后的空白,固定margin_bytes。判断此轮是否应该是没人声了,用的是音量低于人声持续超过terminate_bytes(3秒),所以terminate_bytes必须>=margin_bytes。
四、短声音
在识别时,有个参数是说话最小长度(min_voice_len)。在不同阶段,会有不同。
- 机器人空闲时,要叫机器人去做事,这命令的话可以适当长点。而且长点可以避免短噪音。
- 机器人在执行某个任务,中间会出现问答。有时用户回答时,可能就两个字,像“是的”,“不是”,这时最小长度得变短。
- 虽然是在任务中,但正在移动时,还是不允许短声音。一来移动会产生响动,容易产生噪音。二来既已在移动,意味着机器人不期待用户有回答,用户和机器人说话,极可能是要求机器人做其它事,见1,这命令会满足一定长度。
目前用的normal_min_voice_len是550毫秒,short_min_voice_len是100毫秒。布尔变量allow_short_voice_指示当前是否允许短声音。
五、科大讯飞语音识别
tleagor_speech在实现语音识别时,调用科大讯飞语音识别SDK。SDK是动态库方式,即windows上的msc.dll,android上的libmsc.so。
launcher是以动态方式加载msc.dll/libmsc.so。在获取库中某个地址时,该函数必须有“MSPAPI/__stdcall”修饰符。否则变成__cdecl,那会导致程序崩溃。
为安全,android对允许动态方式加载的动态库文件名做了限制,只允许:libroseaplt.x、libroseaplt2.x、libroseaplt3.x、libroseaplt4.x。libroseaplt.x有专门用途,那只能在2/3/4中选一个。
tleagor_speech集成的科大讯飞语音识别算法是免费的,有每天识别次数限制。自写、还是用讯飞的话,去讯飞官网申请个账号。