
一、tintegrate::add_text_item
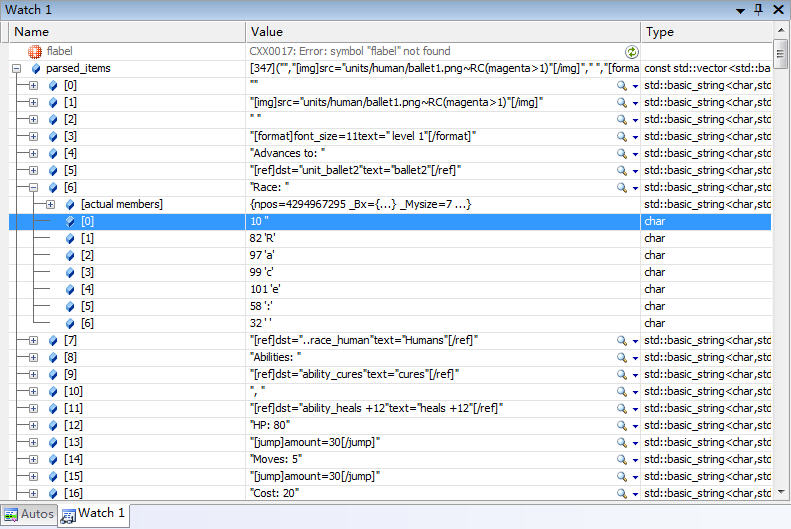
混排使用的字符串
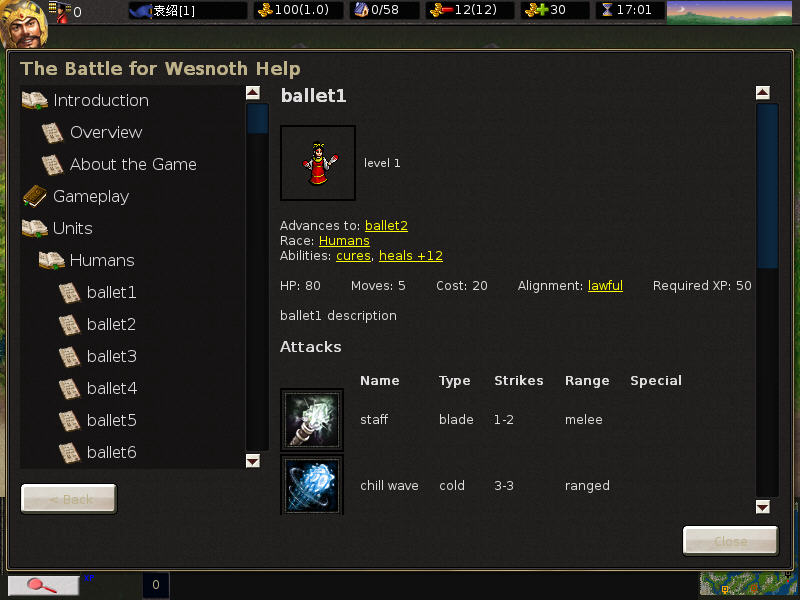
混排效果
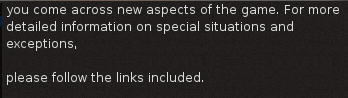
tintegrate::add_text_item中三个显示时执行、可编辑器时不执行
1、“execptions,”和“please”之间那个空行,在换行前即使有空格,只是为显示的话可以不显示。
2、该行剩余空间容得下“detailed”却容不下“ detailed”,则意味着接下一定要换行。既然要换行,只是显示的话,可以去掉之前空格。
first_word_before = " detailed" first_word_after = "detailed"
3、判断第一个单词是否可以继续写在该行,如果不能写意味着一定要下行开始,这样可以不显示第一个单词的第一个空格。
“ detailed”一定得下行开始,那么第一个空格就可以不显示了。
<img>标签
curr_loc_:在创建单元项建使用的、用于指示当前输入位置的坐标(单位:像素)。下一单元将从该坐标开始。
get_min_x(const int y, const int height)。
get_y_for_floating_img(width, xpos, ypos)
语法:<img>src="" align=left|middle|right|back|here float=yes|no box=yes|no<img>
- align:指示如何对齐。所有值都会影响水平方向,BACK还会影响垂直方向。
here:继续从当前放置点(curr_loc_)放置。
left:放置在该行左侧,如果不能放置在左侧,像放置位置的x已不是0,那要新起一行。
middle:放置在该行中间。如果不能放置在中间,像放置位置的x已在中央之后,那要新起一行。
right:放置在该行右侧。如果不能放置在右侧,像放置位置之后、再连上它要超过宽度,那要新起一行。
back:在上个单元的左上角处放置。它必须存在上个单元。如果不存在上个单元,它将被等于同“here”。 - box:指示是否要在该图像周周围放置一个矩形框。矩形框的四条边框度都是2,一旦放置,该图像所占区域的宽度将增加4、高度增加4。
- float:指示是否浮动。不浮动时,单元将以align计算出的为放置坐标;浮动时,
每个单元有两种矩形:绘画矩形、布局矩形。绘画矩形是单元绘画在的矩形;布局矩形是布局时把某一块认为是它的矩形。绘画矩形总是布局矩形的子集。

文本单元后紧跟的“\n”属于该单元,它计入src_size但不计入text;图像单元紧跟的“\n”属于该单元,但不计入src_size。
calculate_cursor计算出的光标位置是放在以src_pos为索引的字符之前。
调整一行内各单元高度逻辑。1)分析每一个单元,直到一行结束,计算出这些单元最大高度curr_row_height_;2)根据curr_row_height_和特定单元高度调整该单元要放置y坐标(tintegrate::adjust_last_row)。
二、text_box、scrollbar_text_box
did_cursor_moved
只有tscroll_text_box会处理这事件,app不须要。当改变了光标位置时会调用这函数。功能:根据光标到达的位置,有必要的话修正item_position。

(1)当光标落在1)行时,由于顶部有一小部分没在视区,did_cursor_moved会修正item_position,以让那部分出现在视区。(2)(1)当光标落在4)行时,由于底部有一小部分没在视区,did_cursor_moved会修正item_position,以让那部分出现在视区。
三、word_wrap_text
处理字符串,在不超过max_width容许宽度下自动插入换行符(\n)生成多行字符串。
语法
std::string word_wrap_text(const std::string& unwrapped_text, int font_sz, int max_width,
int max_lines, const int attention_min_chars)参数
| unwrapped_text | 要处理的字符串 |
| font_sz | 字号 |
| max_width | 最大容许宽度。必须>0 |
| max_lines | 如果设置了>0,生成字符串只要有了它指定的行数,就可以结束处理了。split_in_width就设置1,使得只需得到一行,免得一定要处理整串unwrapped_text |
| attention_min_chars | 必须>0。它指的是一个“字”中一旦超过这个字符数,那要开始调用line_size进行计算,而不是说一个“字”最多只能有的这么个字符数。详细作用参考注释。 |
返回值
返回被换行后的字符串。注意,一旦设了max_lines,返回的可能不是和unwrapped_text对应的整串字符。由于换行符“\n”要等到有下一行有效时才追加,所有返回值的最后字符不会是追加的“\n”。举个例子,当max_lines=1时,它返回的只是第一行内容,不会有追加的“\n”。
当内容中有换行符时,这换行符被放在了下一行。举个例子,有这么个输入字符串“where are you form?\nI' am from.”,那第一行是“where are you from?”,不包括那个换行符。
范例
<example>
注释
说下一个概念:“字”。在处理时“字”中字符串将做为一个整体,理论上它们将不能被分割。那什么样的是一个“字”?一)被“空格”、“\n”隔开的。二)前面已有字符串,但又遇到这么个字符,同时满足了1)它可以和前面隔开,而已有字符中最后一个字符允许和后面隔开,2)已有字符中的最后一个字符允许和后面隔开,它可以和前面隔开。
如果严格按“字”的长度去截断,可能会存在由于“字”太长(举个例子,故意输入没有空格的纯英文字符串)超过了参数限定的最大容许宽度(max_width),而满足max_width的优先级要高于“字”。为此采用方法是在形成“字”的过程中,要实时计算该“字”长度,一旦超过max_width,强制截断。这里就有个效率问题,如果“字”每加一个字符都计算一次长度,这会增加计算量,于是增加了叫attention_min_chars参数,只有“字”中字符数超过了attention_min_chars,才会去调用line_size计算字长。也就是说,一旦内容中存在着字符数<=attention_min_chars的“字”,而它又超过max_width,本函数将产生异常。那如何设置attention_min_chars?
int attention_min_chars = width / font_size;
if (attention_min_chars <= 0) {
attention_min_chars = 10;
} else if (attention_min_chars > 20) {
attention_min_chars = 20;
}直观看上,font_size约等于字高,假设以全是“正方”字符(“%”)去对待,那width下最多能让出现的就是width/font_size。
相关类、函数
bool no_break_before(const wchart_t ch)。指示ch是否能和前面的字符串分开,true表示不能隔开,false表示可以。那什么样的字符是属于要返回true的字符?像“、”、“。”、“}”。
bool no_break_after(const wchar_t ch)。它类似no_break_before,指示ch是否能和后面的字符串分开,true表示不能隔开,false表示可以。那什么样的字符是属于要返回true的字符?像“<”、“[”、“{”。
bool is_cjk_char(const wchar_t ch)。指示ch是否是中日韩汉字,true表示是中日韩汉字,false则不是。一旦是中日韩汉字,那意味着它可以单独成“字”,即可以和前面断开,也可以和后面断开。
四、tintegrate
tintegrate在编辑状态时,要强制去掉“\r”,为什么?\r会占一个字符,会使得处理编辑框变得复杂。举个例子,backspace,1)光标在是下一行头处,在删除上一行的\n同时应该删除\r。2)光标在本行尾处,除了要删除前面那字符,还须要删除紧跟的\r。3)在Windows,SDL会保证复制到剪贴板内容都含有\r。
tintegrate内部会把src解析到items_(std::list<titem>),以下是产生items_的逻辑。
- 不断枚举字符,一直到超过了max_width或遇到标签,之前遍历的内容形成一个titem。
- 继续步骤一,直到枚举到完所有字符。
- 最后个字符是“\n”,会出一个额外的titem,该item的src_size是0,pos是src_长度,text是空。
如何区分一个titem是本身有换行符产生的,还是由自动换行产生的?last_row_指示该行已经解析出的titem,当遇到“\n”,此时它是empty意味着该“\n”是该行第一个titem。
get_first_word:返回字符串的第一个单词。对英文:单词间已空隔分开,对中文测是一个汉字。
makeup_pos、pos、text、src_size
text。字符串缓存。不管是max_width导致的换行还是内容有换行符导致的换行,text末尾都不包括那个换行符。为不什么不包括?——省空间。
markup_pos。此个item在源字符串中的偏移。
pos。此个item的text部分在源字符串中的偏移。
src_size。只有编辑状态时才会生成。1)是text类型的titem时,此个item在源字符串中对应的字符数(包括后面的“\n”)。
markup_pos src_size
0, 43
43, 52
95, 47
142, 3
145, 38
183, 52
235, 37
272, 3
275, 2
277, 44
item[n+1].markup_pos = item[n].markup_pos + item[n].src_size
假设M是最后项,那item[M].markup_pos + item[M].src_size = src.size()
对src_size,重点注意它对应的是源字符串,不会增、减源字符串。所以可得出这么些结论,1)因为超过max_width导致的换行,src_size不会计入那个换行符,原因是这换行符原字符串是没有的。2)当内容中有转义符时,src_size要累加转义符“\”,原因是源字符串中有“\”。
quote_require_escape:指示内容区出现“"”时是否要加转义符。
- quote_require_escape=true的src_中,内容中的“"”前面要加转义符。内容不包括前后两个“"”。
- 操作编辑框,向quote_require_escape=true的titem插入字符时,补转义符的操作是tintegrate::insert_str执行,不是ttext_box层(目的是让ttext_box透明,ttext_box不知道此刻的titem中quote_require_escape是true还是false)。
- app调用set_label时,字符串参数是需要转义符过的。
- ttext_box调用insert_str时,要用tintegrate::insert_str的返回值,而不是根据原字符串+插入字符串自动计算。
- 密码框不允许出现markup。因而密码框不存在转义问题。
在titem内部,quote_require_escape和指示该titem是否是text类的markup是等价的。
五、tintegrate::substr_from_src
从src_提取一串连续字符。
语法
std::string tintegrate::substr_from_src(int from, int to) const
参数
| from | 基于titem.text角度看的起始偏移 |
| to | 基于titem.text角度看的结束偏移,不包括to指向的字符。默认是1048576,即提取from开始的所有数据。 |
返回值
从src_提取出的字符串,[from, to),一定是连续的。
范例
<Example>
注释
from、to由两部分组成,titem.pos + titem.text内偏移。正是因为这两部分是分散的,第二个参数用表示偏移位置的to,而不是size。
如果from所在的titem是markup,而且from落在了标识辅助字节上,这时分两种情况,1)落在前半部分,像<format>,那后向跳到本titem的pos处。2)落在后半部分,像</format>,那落在下一个titem的pos处。——总之都是向后跳到最近一个的pos。to在这方面不作修正,当不使用1048576时,调用程序需确保该参数值。
相关类、函数
<Relative class, function>