
术语
- req_header。http请求中的头部部分。
- req_body。http请求中的body部分。HttpRequestInfo的upload_data_stream存储着req_body,没有时这个指针是nullptr。
- resp_header。http应答中的头部部分。
- resp_body。http应答中的body部分。
一、一次http会话
一次http会话包括发送http请求、接收http应答。
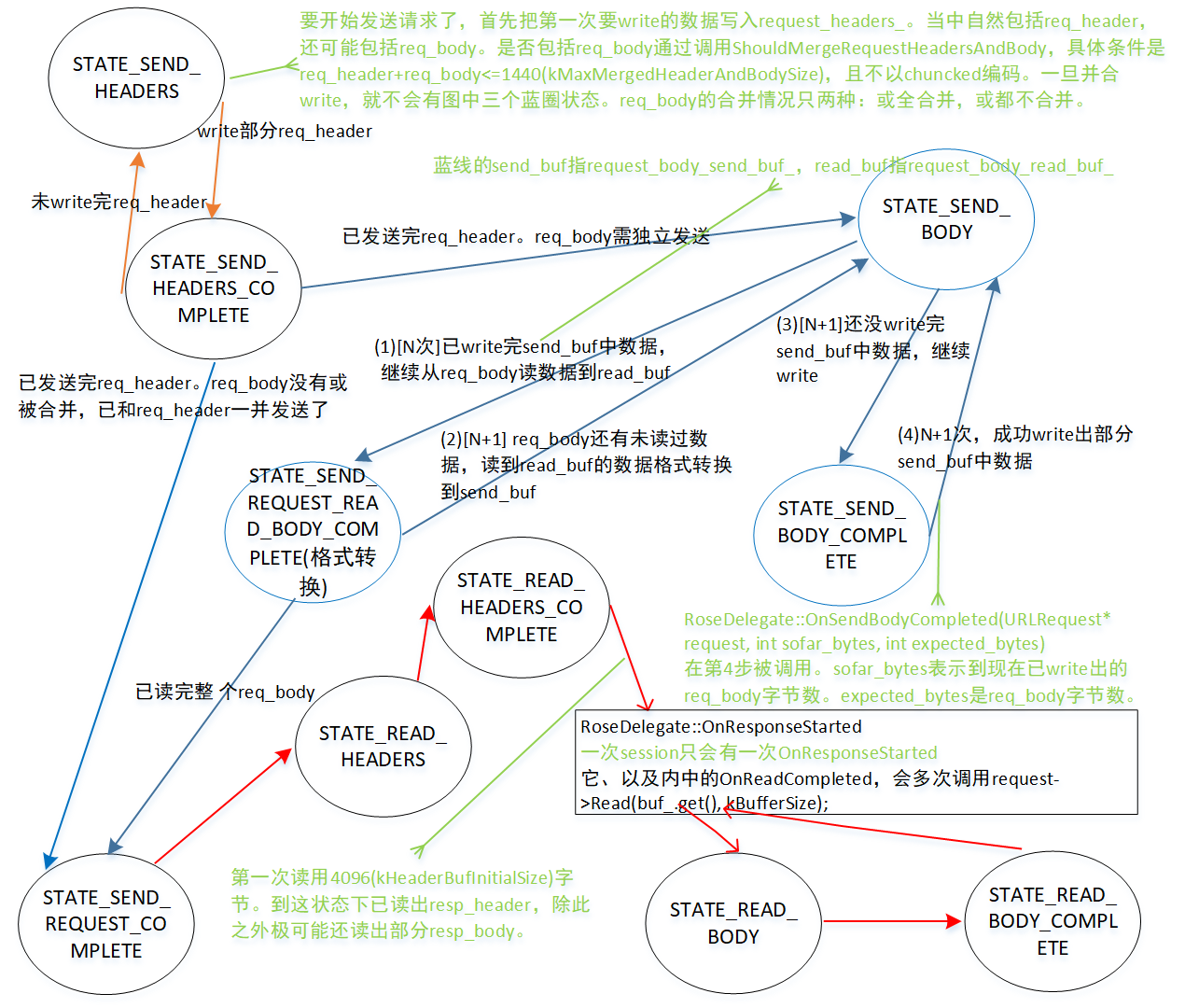
1.1 发送http请求
图1中金色、蓝色部分是发送http请求。
req_body有可能被合并到req_header,然后一块发送。要开始发送请求了,首先把第一次要write的数据写入request_headers_。当中自然包括req_header,还可能包括req_body。是否包括req_body通过调用ShouldMergeRequestHeadersAndBody,具体条件是req_header+req_body<=1440(kMaxMergedHeaderAndBodySize),且不以chuncked编码。一旦并合write,就不会有图中三个蓝圈状态。req_body的合并情况只两种:或全合并,或都不合并。
独立发送req_body要额外三个状态,这是不是过于复杂了?——复杂有两个原因,一是app直接给出的req_body有时并不能直接发向socket,像使用了chunked编码,这就需要转换格式。二是req_body可能较大,要分多次发送,目前一次最多发送16K字节(kRequestBodyBufferSize)。
因为可能存在编码,发送就有了以下逻辑。从req_body取16K字节到request_body_read_buf_,经过编码后放到request_body_send_buf_,最后write到socket。这三个步骤被16K一次重复执行,直到发送完req_body。request_body_read_buf_和request_body_send_buf_都和req_body有关,和resp_body无关。对确实需要转换格式的场景,像chunked,它们存的数据不一样。对直接可以发送的场景,像json,指向的是同一个SeekableIOBuffer,连复制都不需要。
为加深对两处buf理解,看下STATE_SEND_BODY状态对应的执行函数DoSendBody。
case STATE_SEND_BODY==>
int HttpStreamParser::DoSendBody() {
if (request_body_send_buf_->BytesRemaining() > 0) {
// 还没write完第N次从req_body读出的数据,继续write。write时使用的是request_body_send_buf_。
io_state_ = STATE_SEND_BODY_COMPLETE;
return connection_->socket()->Write(
request_body_send_buf_.get(), request_body_send_buf_->BytesRemaining(),
io_callback_, NetworkTrafficAnnotationTag(traffic_annotation_));
}
if (request_->upload_data_stream->is_chunked() && sent_last_chunk_) {
// Finished sending the request.
io_state_ = STATE_SEND_REQUEST_COMPLETE;
return OK;
}
// 已发送完第N次从req_body读出的数据,继续从req_body读数据到request_body_read_buf_。如果已经读完req_body,下面的Read会返回0。这个Read是从内存读数据,不是网络读,返回0不表示错误,是告知没数据了。
request_body_read_buf_->Clear();
io_state_ = STATE_SEND_REQUEST_READ_BODY_COMPLETE;
// 在STATE_SEND_REQUEST_READ_BODY_COMPLETE下,如果Read出数据,那格式转换后进入STATE_SEND_BODY,否则进入STATE_SEND_REQUEST_COMPLETE,完成了此次发送http请求。
return request_->upload_data_stream->Read(
request_body_read_buf_.get(), request_body_read_buf_->capacity(),
base::BindOnce(&HttpStreamParser::OnIOComplete,
weak_ptr_factory_.GetWeakPtr()));
}1.2 接收http应答
图1中红色部分是接收http应答。
发送http请求可说在HttpStreamParser内部就走完整个流程,接收http应答则不是,app实现的OnResponseStarted(URLRequest::Delegate的虚函数)要横插一杠。总的逻辑:HttpStreamParser读出resp_header后(STATE_READ_HEADERS_COMPLETE),会调用OnResponseStarted,在此函数内,要多次调用URLRequest::Read。Read会再次进入HttpStreamParser,每一次Read会执行STATE_READ_BODY到STATE_READ_BODY_COMPLETE状态转换。一次Read最多读4096(kBufferSize)字节,重复多次Read,直接读完resp_body。
为加深理解,看下STATE_READ_BODY状态对应的执行函数DoReadBody。当然DoReadBody不仅仅用于第一次读resp_body,一样用于后绪的读。
STATE_READ_BODY==>
int HttpStreamParser::DoReadBody() {
io_state_ = STATE_READ_BODY_COMPLETE;
// Added to investigate crbug.com/499663.
CHECK(user_read_buf_.get());
// There may be some data left over from reading the response headers.
// 第一次Read socket时,读到的数据放在read_buf_。read_buf_->offset()指示read_buf_有效的字节数。
if (read_buf_->offset()) {
// 第一次读时有可能读出部分resp_body,read_buf_unused_offset_是resp_header的字节数,因而available就是第一次读出的resp_body字节数。
int available = read_buf_->offset() - read_buf_unused_offset_;
if (available) {
CHECK_GT(available, 0);
int bytes_from_buffer = std::min(available, user_read_buf_len_);
// 此处的user_read_buf_就是request->Read(buf_.get(), kBufferSize)时的buf_。
memcpy(user_read_buf_->data(),
read_buf_->StartOfBuffer() + read_buf_unused_offset_,
bytes_from_buffer);
read_buf_unused_offset_ += bytes_from_buffer;
if (bytes_from_buffer == available) {
read_buf_->SetCapacity(0);
read_buf_unused_offset_ = 0;
}
return bytes_from_buffer;
} else {
read_buf_->SetCapacity(0);
read_buf_unused_offset_ = 0;
}
}
// 第一次读出的read_buf_已没了数据,继续向socket要数据
// Check to see if we're done reading.
if (IsResponseBodyComplete())
return 0;
// resp_body应该还没读完,继续向socket要数据,此时读出的数据直接放在了request->Read给的user_read_buf_。
DCHECK_EQ(0, read_buf_->offset());
return connection_->socket()
->Read(user_read_buf_.get(), user_read_buf_len_, io_callback_);
}一次http会话只会调用一次RoseDelegate::OnResponseStarted。上面有说它在STATE_READ_HEADERS_COMPLETE后被调用,到这状态时已读出resp_header,除此之外极可能还读出部分resp_body。举个例子,假设resp_header是84字节,第一次向socket读时会读4096字节(kHeaderBufInitialSize),于是读出的数据中就有4012个字节是属于resp_body。注意,4012字节可能并不全是app直接发出的resp_body,像chunked编码时当中会含有数个字节的chunked头([chunk size][\r\n])。剔除chunked头后,假设剩余字节数是4006,4006字节就是URLRequest::Read的返回值。
void RoseDelegate::OnResponseStarted(URLRequest* request, int net_error) {
...
// Initiate the first read.
// Delegate的第一次读,由于之前STATE_READ_HEADERS_COMPLETE已读取部分resp_body,此次其实不会触发socket read,只是把之前读出的数据复制向buf_,返回值bytes_read是4006。
int bytes_read = request->Read(buf_.get(), kBufferSize);
if (bytes_read >= 0)
OnReadCompleted(request, bytes_read);
else if (bytes_read != ERR_IO_PENDING)
OnResponseCompleted(request);
}以上的OnResponseStarted只看到第一次request->Read,子函数OnReadCompleted会触发后绪Read。
void RoseDelegate::OnReadCompleted(URLRequest* request, int bytes_read)
{
...
// expected_size是resp_body可能字节数。只能说是可能,因为有时算不出,像使用chunked,这时expected_size值是-1。
const int64_t expected_size = request->GetExpectedContentSize();
if (bytes_read >= 0) {
// 这个bytes_read是OnResponseStarted之前(第一次Read)读出的字节数
received_bytes_count_ += bytes_read;
// 已确定累计读出了received_bytes_count_字节的resp_body。Rose会在这里增加读取resp_body的进度提示。
// data_received_是最后存放读出的resp_body的地方,是app直接访问resp_body的变量。
data_received_.append(buf_->data(), bytes_read);
...
}
// If it was not end of stream, request to read more.
while (bytes_read > 0) {
bytes_read = request->Read(buf_.get(), kBufferSize);
if (bytes_read > 0) {
// 后绪Read又读出了bytes_read字节
data_received_.append(buf_->data(), bytes_read);
received_bytes_count_ += bytes_read;
// 已确定累计读出了received_bytes_count_字节的resp_body。Rose会在这里增加读取resp_body的进度提示。
...
}
}
request_status_ = bytes_read;
if (request_status_ != ERR_IO_PENDING) {
OnResponseCompleted(request);
} else if (cancel_in_rd_pending_) {
request_status_ = request->Cancel();
}
}小结为读取resp_body开辟的缓冲区情况。假设resp_body有4M字节,那至少需要4K+4M字节缓存,4K用于一次URLRequest::Read,4M是resp_body最后存放到的data_received_。
二、https
- 根据url中的scheme部分判断是否要用ssl,判断函数:HttpStreamFactory::Job::GetSocketGroup()。scheme是https时SSL_GROUP,否则NORMAL_GROUP。该值后绪转成一个叫using_ssl的bool变量:bool using_ssl = group_type == ClientSocketPoolManager::SSL_GROUP。
- [connect_job.cc]CreateConnectJob要为此次会话创建一个派生于ConnectJob的对象。using_ssl==true时,创建的对象是SSLConnectJob,否则创建的是TransportConnectJob。
- 在“int SSLConnectJob::DoLoop(int result)”,执行connect,以及处理SSL协商的SSLClientSocketImpl::DoHandshakeLoop。
- 构造HttpStreamParser,执行“int HttpStreamParser::DoLoop(int result)”,内中处理发送http请求、接收http应答。
如何从SSLConnectJob::DoLoop到HttpStreamParser::DoLoop?——SSLConnectJob::DoLoop、HttpStreamParser::DoLoop都是HttpNetworkTransaction::DoLoop的子过程,由HttpNetworkTransaction负责转换。
int HttpNetworkTransaction::DoLoop(int result) { DCHECK(next_state_ != STATE_NONE); int rv = result; do { State state = next_state_; next_state_ = STATE_NONE; switch (state) { case STATE_NOTIFY_BEFORE_CREATE_STREAM: DCHECK_EQ(OK, rv); rv = DoNotifyBeforeCreateStream(); break; case STATE_CREATE_STREAM: DCHECK_EQ(OK, rv); // 在DoCreateStream会执行第二步的CreateConnectJob,以及开始执行第三步的SSLConnectJob::DoLoop。 rv = DoCreateStream(); break; case STATE_CREATE_STREAM_COMPLETE: rv = DoCreateStreamComplete(rv); break; case STATE_INIT_STREAM: DCHECK_EQ(OK, rv); // 在DoInitStream会构造HttpStreamParser::HttpStreamParser。 rv = DoInitStream(); break; case STATE_INIT_STREAM_COMPLETE: rv = DoInitStreamComplete(rv); break; ... case STATE_BUILD_REQUEST: DCHECK_EQ(OK, rv); net_log_.BeginEvent(NetLogEventType::HTTP_TRANSACTION_SEND_REQUEST); rv = DoBuildRequest(); break; case STATE_BUILD_REQUEST_COMPLETE: rv = DoBuildRequestComplete(rv); break; case STATE_SEND_REQUEST: DCHECK_EQ(OK, rv); // DoSendRequest开始执行HttpStreamParser::DoLoop rv = DoSendRequest(); break; case STATE_SEND_REQUEST_COMPLETE: rv = DoSendRequestComplete(rv); net_log_.EndEventWithNetErrorCode( NetLogEventType::HTTP_TRANSACTION_SEND_REQUEST, rv); break; ... default: NOTREACHED() << "bad state"; rv = ERR_FAILED; break; } } while (rv != ERR_IO_PENDING && next_state_ != STATE_NONE); return rv; }
三、调试ssl协议
假设server的ssl端口是8040,在该端口,首先执行的是ssl握手协议。
- client --> server:Client Hello。
- server --> client:握手协议中的应答,包括5字节的sll头,内容是Server Hello、Certificate、Server Key Exchabge、Server Hello Done这4个消息。
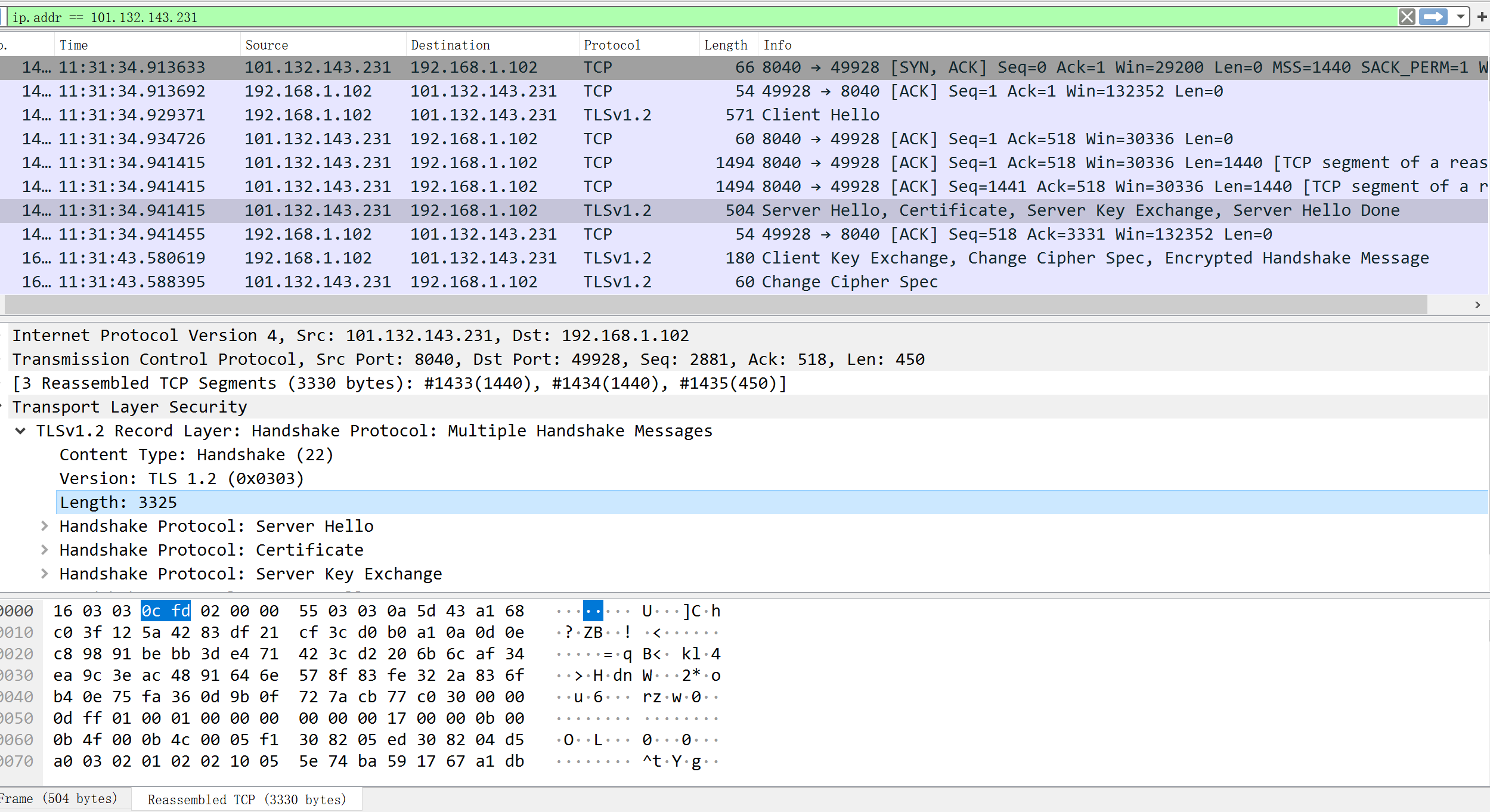
client收到的第一个应答是握手协议中的应答。正如图2所示,有3330字节,首先是5字节的ssl头,后面3325字节是4个消息,其中Certificate存储的就是证书。由图中可以看到,握手协议都是明文。对应到C++代码,何时收到这个应答?
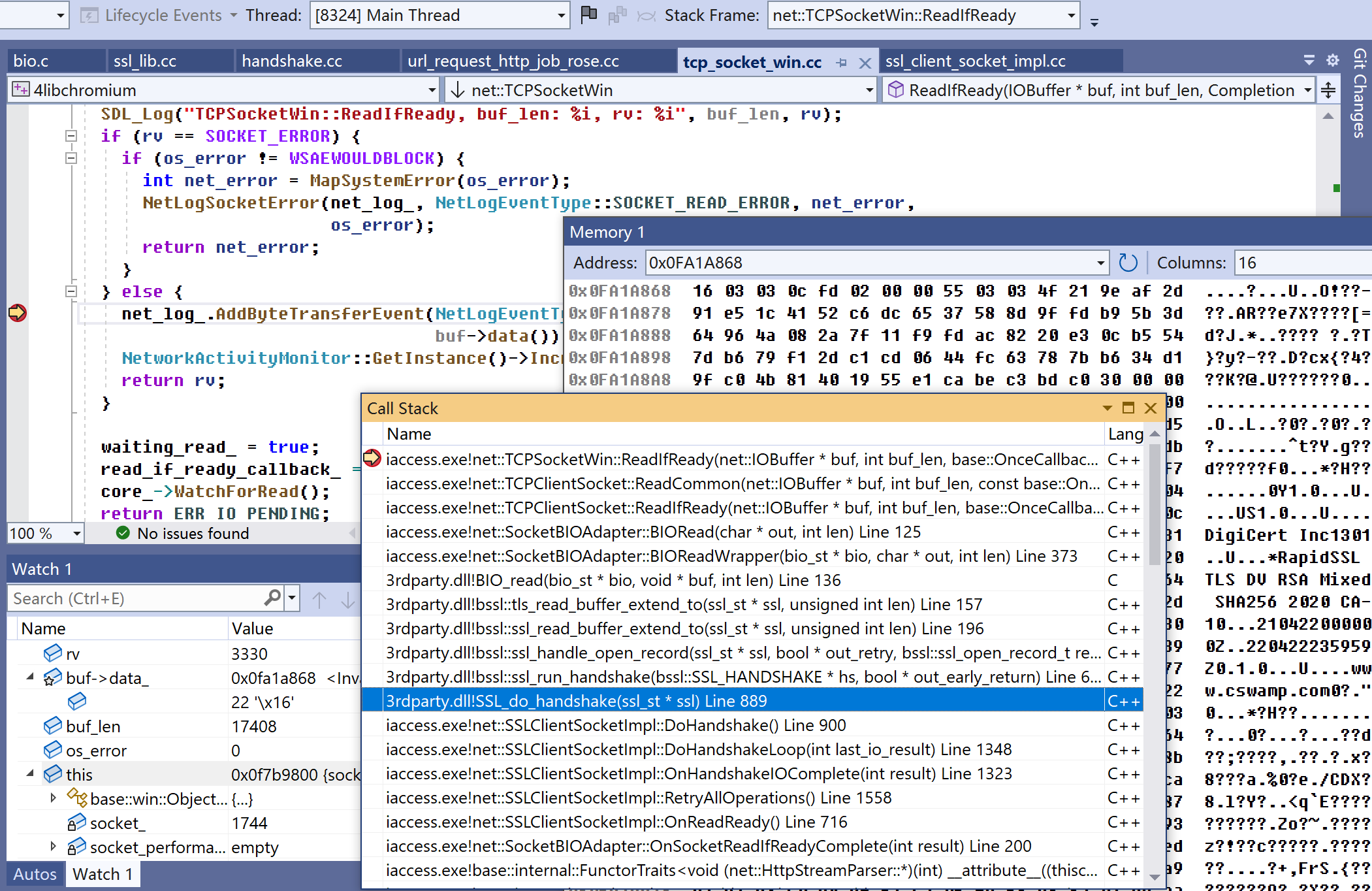
图3中,recv是socket api,chromium用的是异步方式,应而第一次进入TCPSocketWin::ReadIfReady时,满足“rv == SOCKET_ERROR && os_error != WSAEWOULDBLOCK”,ReadIfReady返回ERR_IO_PENDING。第二次进入TCPSocketWin::ReadIfReady才会收到图中的3330字节。
通过查看图3的函数栈,会发现此刻TCPSocketWin::ReadIfReady正处在上面“二、https”说到的SSLClientSocketImpl::DoHandshakeLoop。高亮行SSL_do_handshake表示开始进入boringssl代码。
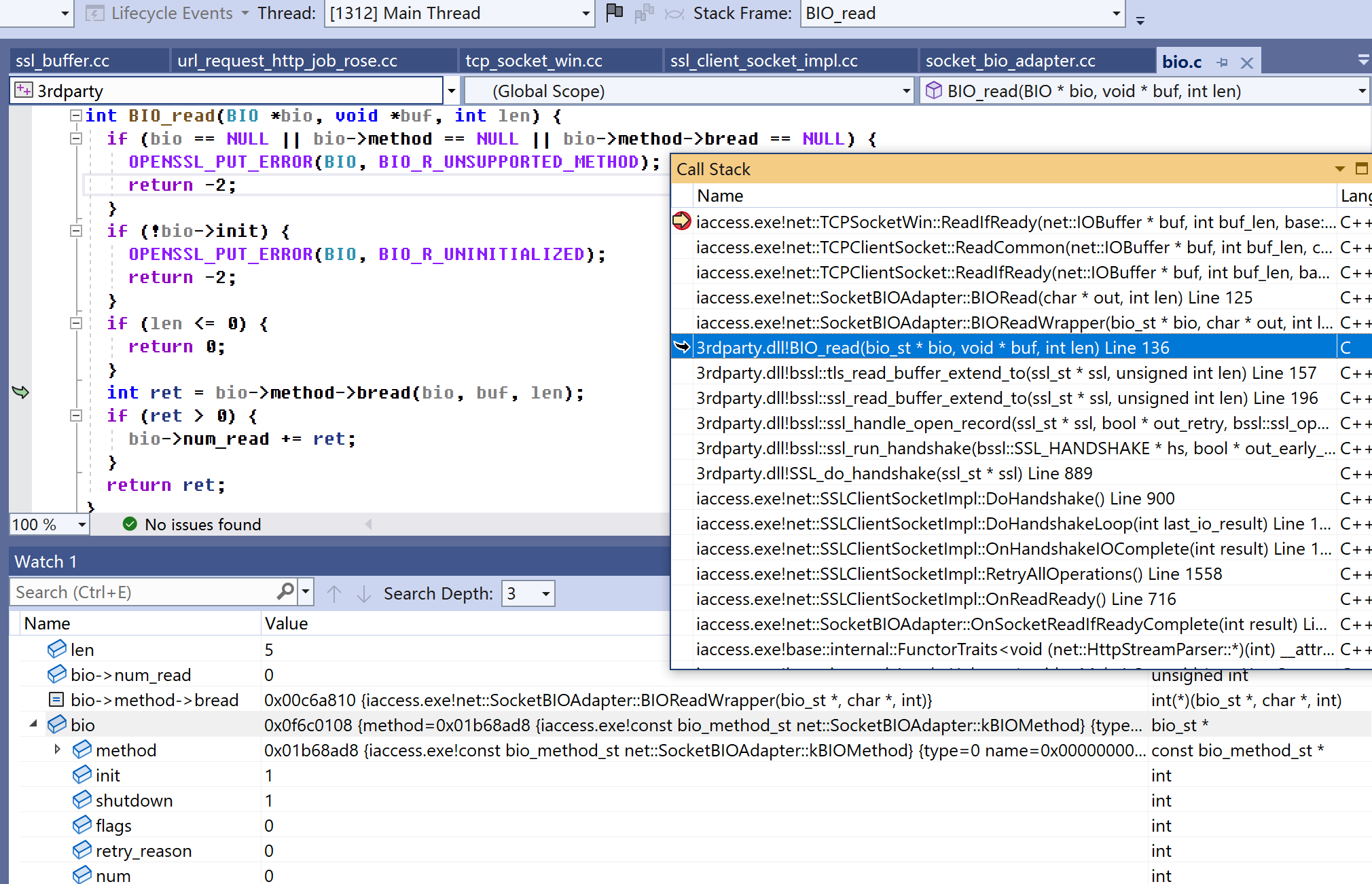
图4是时BIO_read。参数len的值是5,也就是说上层ssl_run_handshake其实只希望读5个字节,即ssl头。上面已知道TCPSocketWin::ReadIfReady此刻读出3330字节,当然不可能丢掉这多出的3325字节,如何处理见函数栈中的SocketBIOAdapter::BIORead。
在图4,一旦bio->method->bread返回,存储返回值的ret变量值是5,不是3330。