
opencv优化函数效率的方法分两种:HAL和根据正运行在的cpu指令集,其中HAL的优先级要高于cpu指令集。
- CALL_HAL。试图对某个函数进行HAL优化。如果能够优化,所在函数就执行结束,否则须要执行后绪的根据指令集优化。
- CV_CPU_DISPATCH。试图对某个函数进行依据cpu指令集优化。一个cpu会支持多种可优化指令集,和此操作关联的CV_CPU_DISPATCH_MODES_ALL宏指明了尝试这些指令集的次序,所以效率越高的指令集前越靠前。ALL中的最后一个总是BASELINE,它表示以通常的cpu指令集执行该函数。
- cmake会生成cpu指令集优化的相关cpp文件,编译这些cpp时,需要在文件层额外定义CV_CPU_DISPATCH_MODE=<xxx>。以AVX2为例,需定义CV_CPU_DISPATCH_MODE=AVX2。
- 要是不编译cmake生成的cpu指令集优化相关cpp文件,理论上链接时会报unresolved external symbol。
- 某种cpu指令集优化既不属于baseline features,也不属于dispatched features,编译出的opencv库将不会对该指令集优化,即使cmake自动生成了该集指令的相关cpp文件。
一、优化过程
cv::Mat mat1(cv::Size(4, 1), CV_32FC1), mat2(cv::Size(4, 1), CV_32FC1), mat3; mat1.at<float>(0, 0) = 1; mat2.at<float>(0, 0) = 1; mat1.at<float>(0, 1) = 1; mat2.at<float>(0, 1) = -1; mat1.at<float>(0, 2) = -1; mat2.at<float>(0, 2) = 1; mat1.at<float>(0, 3) = -1; mat2.at<float>(0, 3) = -1; cv::phase(mat1, mat2, mat3, true);
执行以上语句会进入cv::hal::fastAtan32f,让以fastAtan32f为例,描述OpenCV对函数的优化过程。
modules/core/src/mathfuncs_core.dispatch.cpp
------------------------------------------
#include "mathfuncs_core.simd.hpp"
#include "mathfuncs_core.simd_declarations.hpp" // defines CV_CPU_DISPATCH_MODES_ALL=AVX2,...,BASELINE based on CMakeLists.txt content
void fastAtan32f(const float *Y, const float *X, float *angle, int len, bool angleInDegrees)
{
CV_INSTRUMENT_REGION()
CALL_HAL(fastAtan32f, cv_hal_fastAtan32f, Y, X, angle, len, angleInDegrees);
CV_CPU_DISPATCH(fastAtan32f, (Y, X, angle, len, angleInDegrees),
CV_CPU_DISPATCH_MODES_ALL);
}让深入CALL_HAL。
#define CALL_HAL(name, fun, ...) \
{ \
int res = __CV_EXPAND(fun(__VA_ARGS__)); \
if (res == CV_HAL_ERROR_OK) \
return; \
else if (res != CV_HAL_ERROR_NOT_IMPLEMENTED) \
CV_Error_(cv::Error::StsInternal, \
("HAL implementation " CVAUX_STR(name) " ==> " CVAUX_STR(fun) " returned %d (0x%08x)", res, res)); \
}
#define cv_hal_fastAtan32f hal_ni_fastAtan32f
inline int hal_ni_fastAtan32f(const float* y, const float* x, float* dst, int len, bool angleInDegrees) { return CV_HAL_ERROR_NOT_IMPLEMENTED; }
CALL_HAL逻辑是这样的:如果HAL能对fun进行优化,res=CV_HAL_ERROR_OK指示执行操作了,并结束所在函数,否则res=CV_HAL_ERROR_NOT_IMPLEMENTED。这里假设没有用HAL优化(HAL优化见下文的“四、HAL优化”),针对fun=cv_hal_fastAtan32f,CALL_HAL最后执行hal_ni_fastAtan32f,它就是空操作,但由于返回CV_HAL_ERROR_NOT_IMPLEMENTED,调用它的fastAtan32f会继续执行后面的CV_CPU_DISPATCH。在深入这宏前让介绍mathfuncs_core.dispatch.cpp中一开始就执行的两条include语句。
#include "mathfuncs_core.simd.hpp" #include "mathfuncs_core.simd_declarations.hpp"
第一个include作用是两个,1)声明cpu_baseline版本,2)实现baseline版本,这是通过不定义CV_CPU_OPTIMIZATION_DECLARATIONS_ONLY宏,使得mathfuncs_core.simd.hpp包含实现。
第二个include也两个作用,1)声明特殊指令集版本(只是声明),2)定义一个叫CV_CPU_DISPATCH_MODES_ALL的宏。
mathfuncs_core.simd_declarations.hpp是一个cmake生成的文件 ----------------------------------------------- #define CV_CPU_SIMD_FILENAME "C:/ddksample/opencv/modules/core/src/mathfuncs_core.simd.hpp" #define CV_CPU_DISPATCH_MODE AVX #include "opencv2/core/private/cv_cpu_include_simd_declarations.hpp" #define CV_CPU_DISPATCH_MODE AVX2 #include "opencv2/core/private/cv_cpu_include_simd_declarations.hpp" #define CV_CPU_DISPATCH_MODES_ALL AVX2, AVX, SSE2, BASELINE #undef CV_CPU_SIMD_FILENAME
CV_CPU_DISPATCH_MODES_ALL宏指示了每个模块实现了的指令集版本。它实现了四种指令集,AVX2、AVX、SSE2是特殊指令集,BASELINE则是cpu_baseline实现。
上面四个版本,cpu_baseline的函数已由第一个include实现,三种特殊指令集则由另外三个源文件实现,它们有着一样内容。
#include "precomp.hpp" #include "mathfuncs_core.simd.hpp"
要编译这三个文件,必须在文件层定义一个叫CV_CPU_DISPATCH_MODE的宏,从而出来opt_AVX、opt_AVX2、opt_SSE2版本。
- 文件:mathfuncs_core.avx.cpp。文件层的预定义宏:CV_CPU_DISPATCH_MODE=AVX。最后实现的函数:cv::hal::opt_AVX::fastAtan32f
- 文件:mathfuncs_core.avx2.cpp。文件层的预定义宏:CV_CPU_DISPATCH_MODE=AVX2。最后实现的函数:cv::hal::opt_AVX2::fastAtan32f
- 文件:mathfuncs_core.sse2.cpp。文件层的预定义宏:CV_CPU_DISPATCH_MODE=SSE22。最后实现的函数:cv::hal::opt_SSE2::fastAtan32f
有了这四个版本的fastAtan32f实现,让回到CV_CPU_DISPATCH,看它是如何调用这四个函数。以下这个宏展开后的伪代码。
CV_CPU_DISPATCH(fastAtan32f, (Y, X, angle, len, angleInDegrees), AVX2, AVX, SSE2, baseline)
{
if (cv::checkHardwareSupport(CV_CPU_AVX2) {
cv::hal::opt_AVX2::fastAtan32f(Y, X, angle, len, angleInDegrees);
return;
}
if (cv::checkHardwareSupport(CV_CPU_AVX) {
cv::hal::opt_AVX::fastAtan32f(Y, X, angle, len, angleInDegrees);
return;
}
cv::hal::opt_SSE2::fastAtan32f(Y, X, angle, len, angleInDegrees); return;
cv::hal::cpu_baseline::fastAtan32f(Y, X, angle, len, angleInDegrees); return;
}CV_CPU_DISPATCH_MODES_ALL宏决定了四个fastAtan32f调用次序。要没意外,CV_CPU_DISPATCH的最后两个总是__CV_CPU_DISPATCH_CHAIN_BASELINE, __CV_CPU_DISPATCH_CHAIN_END,后者是个空操作。
#define __CV_CPU_DISPATCH_CHAIN_END(fn, args, mode, ...) /* done */
CV_CPU_DISPATCH中,为什么CV_CPU_AVX2、CV_CPU_AVX会有checkHardwareSupport,SSE2、cpu_baseline则没有,这就涉及到cv_cpu_config.h是如何分类baseline features和dispatched features。
二、cv_cpu_config.h、baseline features和dispatched features
cv_cpu_config.h由cmake生成,指示了要使用的优化设置。以下是一个例子,支持优化指令集:SSE、SSE2、SSE4_1、SSE4_2、FP16、AVX、AVX2。
// OpenCV CPU baseline features #define CV_CPU_COMPILE_SSE 1 #define CV_CPU_BASELINE_COMPILE_SSE 1 #define CV_CPU_COMPILE_SSE2 1 #define CV_CPU_BASELINE_COMPILE_SSE2 1 #define CV_CPU_BASELINE_FEATURES 0 \ , CV_CPU_SSE \ , CV_CPU_SSE2 \ // OpenCV supported CPU dispatched features #define CV_CPU_DISPATCH_COMPILE_SSE4_1 1 #define CV_CPU_DISPATCH_COMPILE_SSE4_2 1 #define CV_CPU_DISPATCH_COMPILE_FP16 1 #define CV_CPU_DISPATCH_COMPILE_AVX 1 #define CV_CPU_DISPATCH_COMPILE_AVX2 1
cv_cpu_config.h定义的cv_cpu_config.h分两种:baseline features,dispatched features。baseline features指的是那些“所有”cpu必须能支持人SIMD。一旦运行在的cpu不支持这种SIMD,app会因为非法而退出(初始收集到此cpu能支持哪些针令集后,就会调用checkFeatures检查是否支持了全部的baseline features)。dispatched features指的是那些会运行时判断是否支持的指令集,即用cv::checkHardwareSupport运行时检查cpu是否能支持这种SIMD。
这两种features有什么作用?——它们影响上面所述的指令集优化CV_CPU_DISPATCH的行为。对dispatched features,会先用cv::checkHardwareSupport进行判断,支持了才会调用执行函数。对baseline features则没有checkHardwareSupport,直接调用。为什么会有这种结果,让以“AVX”为例进行说明。
#if !defined CV_DISABLE_OPTIMIZATION && defined CV_ENABLE_INTRINSICS && defined CV_CPU_COMPILE_AVX # define CV_TRY_AVX 1 # define CV_CPU_HAS_SUPPORT_AVX 1 # define CV_CPU_CALL_AVX(fn, args) return (opt_AVX::fn args) #elif !defined CV_DISABLE_OPTIMIZATION && defined CV_ENABLE_INTRINSICS && defined CV_CPU_DISPATCH_COMPILE_AVX # define CV_TRY_AVX 1 # define CV_CPU_HAS_SUPPORT_AVX (cv::checkHardwareSupport(CV_CPU_AVX)) # define CV_CPU_CALL_AVX(fn, args) if (CV_CPU_HAS_SUPPORT_AVX) return (opt_AVX::fn args) #else # define CV_TRY_AVX 0 # define CV_CPU_HAS_SUPPORT_AVX 0 # define CV_CPU_CALL_AVX(fn, args) #endif #define __CV_CPU_DISPATCH_CHAIN_AVX(fn, args, mode, ...) CV_CPU_CALL_AVX(fn, args); __CV_EXPAND(__CV_CPU_DISPATCH_CHAIN_ ## mode(fn, args, __VA_ARGS__))
当认为AVX是baseline时,即预定义宏CV_CPU_COMPILE_AVX,CV_CPU_CALL_AVX将总是执行opt_AVX::fn。当认为AVX是dispatched时,即预定义宏CV_CPU_DISPATCH_COMPILE_AVX,CV_CPU_CALL_AVX将先用checkHardwareSupport(CV_CPU_AVX)进行判断,true后才执行opt_AVX::fn。如果AVX既不是baseline,也不是dispatched,CV_CPU_CALL_AVX就是个空操作,也就是说编译出的opencv不会有AVX优化。
为让支持更多cpu,应尽可能低的定义baseline features。对_WIN32,当前就是SSE、SSE2。
三、cmake如何生成cpu指令集优化的相关文件
以mathfuncs_core.dispatch.cpp为例,看相关过程。
mathfuncs_core.dispatch.cpp位在<opencv>/modules/core/src目录,打开该目录下的CMakeLists.txt。
<opencv>/modules/core/CMakeLists.txt ocv_add_dispatched_file(mathfuncs_core SSE2 AVX AVX2) ocv_add_dispatched_file(stat SSE4_2 AVX2) ocv_add_dispatched_file(arithm SSE2 SSE4_1 AVX2 VSX3) ocv_add_dispatched_file(convert SSE2 AVX2 VSX3) ocv_add_dispatched_file(convert_scale SSE2 AVX2) ocv_add_dispatched_file(count_non_zero SSE2 AVX2) ocv_add_dispatched_file(matmul SSE2 SSE4_1 AVX2 AVX512_SKX) ocv_add_dispatched_file(mean SSE2 AVX2) ocv_add_dispatched_file(merge SSE2 AVX2) ocv_add_dispatched_file(split SSE2 AVX2) ocv_add_dispatched_file(sum SSE2 AVX2)
上面指出了core要优化哪些cpp。第一个ocv_add_dispatched_file对应mathfuncs_core.dispatch.cpp,指示mathfuncs_core.dispatch.cpp可进行SSE2、AVX、AVX2这三种优化。
在<opencv>目录查找使用了ocv_add_dispatched_file的地方,没找到哪个cpp要优化NEON指令集。对Android,v4.5.1应该没使用neon优化。
四、HAL优化
HAL优化过程请阅读网络一篇文章:“OpenCV中的HAL方法调用流程分析[1] ”。
到这里,我们发现该函数(hal_replacement.hpp定义的hal_ni_resize)直接返回CV_HAL_ERROR_NOT_IMPLEMENTED,按照上面的分析,hal::resize继续往下执行。那么,hal的实现是怎么切入进来的呢?
我们发现,hal_replacement.hpp中的CALL_HAL宏上有一句#include "custom_hal.hpp",好奇怪,include不一般都放在开头嘛?然后我们看下这个custom_hal.cpp,发现它只有一句#include "carotene/tegra_hal.hpp",我们继续跟踪下去。因为前面分析的函数为hal_ni_resize,直接find hal_ni_resize,没有结果。然后我们find cv_hal_resize,发现有:
<opencv>/3rdparty/carotene/hal/tegra_hal.hpp --------- #undef cv_hal_resize #define cv_hal_resize TEGRA_RESIZE顿时就感觉快打通了,这里竟然把cv_hal_resize给undef掉了,我们知道在hal_replacement.hpp中是#define cv_hal_resize hal_ni_resize的,并且从文件的位置来看,这个def就会被undef掉,然后重新定义为TEGRA_RESIZE
custom_hal.hpp由cmake生成,以下是Rose在用的整个custom_hal.hpp。
#ifndef _CUSTOM_HAL_INCLUDED_ #define _CUSTOM_HAL_INCLUDED_ #if defined __ARM_NEON__ || defined __ARM_NEON #include "carotene/tegra_hal.hpp" #endif #endif
__ARM_NEON__、__ARM_NEON,针对arm架构,Android、iOS都是预定义。因而总的是思路是:Android、iOS会使用carotene优化,windows则没有HAL。
要使用HAL优化,除custom_hal.hpp需include tegra_hal.hpp,还须要做以下事。
- 把<opencv>/3rdparty/carotene/hal/tegra_hal.hpp复制到<opencv>/3rdparty/carotene/include/carotene。目的是为了让custom_hal.hpp能打开tegra_hal.hpp。
- 预定义宏:-DCAROTENE_NS=carotene_o4t。目的是把<carotene>/src/*.cpp编译出的函数放入carotene_o4t这个命名空间,否则会被放入carotene。Opencv建议把这个宏定义放到全局。Rose考虑到全局影响太大,改为修改definitions.hpp文件。
<opencv>/3rdparty/carotene/include/carotene/definitions.hpp ------------------ #ifndef CAROTENE_NS #define CAROTENE_NS carotene #endif 改为 #ifndef CAROTENE_NS #define CAROTENE_NS carotene_o4t #endif
- 预定义宏:-DWITH_NEON。Opencv建议把这个宏定义放到全局。Rose考虑到全局影响太大,改为修改CAROTENE_NEON宏的定义条件,去掉WITH_NEON。
#if defined WITH_NEON && (defined __ARM_NEON__ || defined __ARM_NEON) #define CAROTENE_NEON #endif 改为 #if defined __ARM_NEON__ || defined __ARM_NEON #define CAROTENE_NEON #endif
carotene优化的效率怎样?——以cv::resize为例,使用、不使用cartonene的测试结果。硬件平台是firefly AIO3399J。
------------android, 使用cartonene----------------- scale_surface from (4032x3024) == > (2016x1512), used: 19 ms scale_surface from (4032x3024) == > (1344x1008), used: 37 ms scale_surface from (4032x3024) == > (1008x756), used: 24 ms scale_surface from (4032x3024) == > (1511x1311), used: 47 ms scale_surface from (4032x3024) == > (2345x1789), used: 49 ms scale_surface from (4032x3024) == > (4123x3123), used: 120 ms scale_surface from (4032x3024) == > (5123x4123), used: 185 ms ------------android, 不使用cartonene----------------- scale_surface from (4032x3024) == > (2016x1512), used: 14 ms scale_surface from (4032x3024) == > (1344x1008), used: 46 ms scale_surface from (4032x3024) == > (1008x756), used: 23 ms scale_surface from (4032x3024) == > (1511x1311), used: 81 ms scale_surface from (4032x3024) == > (2345x1789), used: 105 ms scale_surface from (4032x3024) == > (4123x3123), used: 228 ms scale_surface from (4032x3024) == > (5123x4123), used: 309 ms
小图像,没优势;图像越大,cartonene效果越明显。
五、visual studio是如何生成cv::hal::opt_AVX2::fastAtan32f函数实现
mathfuncs_core.avx2.cpp。文件层的预定义宏:CV_CPU_DISPATCH_MODE=AVX2。最后实现的函数:cv::hal::opt_AVX2::fastAtan32f
1、预定义宏:CV_CPU_DISPATCH_MODE=AVX2
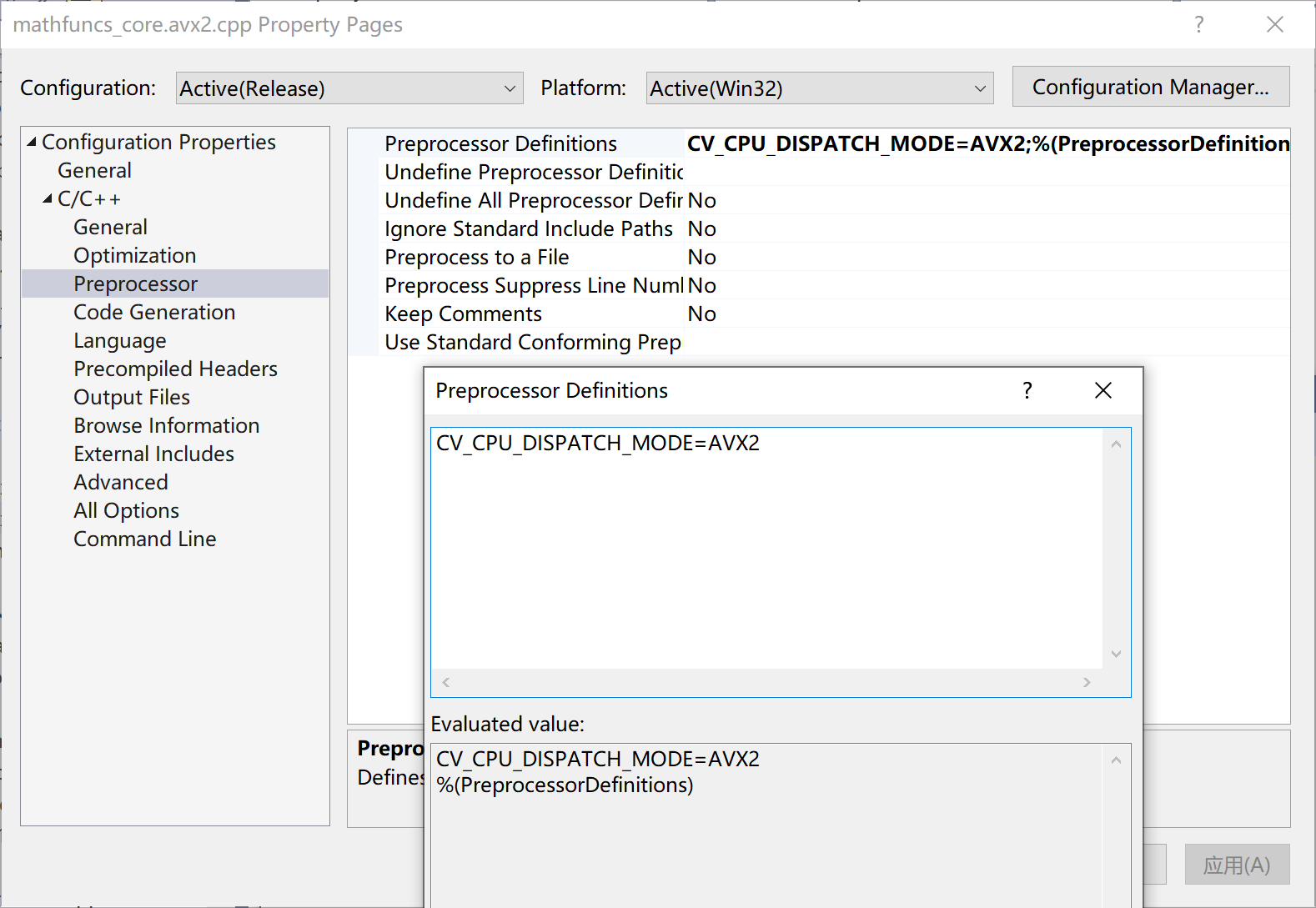
这个宏不能定义为全局宏,单独在文件层定义。“Solution Explorer”找到mathfuncs_core.avx2.cpp,“鼠标右键”,弹出菜单中选“Properties”,“Preprocessor”,定义宏“CV_CPU_DISPATCH_MODE=AVX2”。参考图1。
2、mathfuncs_core.simd.hpp
cmake生成的mathfuncs_core.avx2.cpp ------ #include "../modules/core/src/precomp.hpp" #include "../modules/core/src/mathfuncs_core.simd.hpp"
第一个include和这里讨论没啥关系,进入mathfuncs_core.simd.hpp。
namespace cv { namespace hal { CV_CPU_OPTIMIZATION_NAMESPACE_BEGIN // forward declarations void fastAtan32f(const float *Y, const float *X, float *angle, int len, bool angleInDegrees); ... #ifndef CV_CPU_OPTIMIZATION_DECLARATIONS_ONLY // 编译mathfuncs_core.avx2.cpp时不会定义宏CV_CPU_OPTIMIZATION_DECLARATIONS_ONLY,会进入这里,于是以下实现了cv::hal::opt_AVX2::fastAtan32f函数 void fastAtan32f(const float *Y, const float *X, float *angle, int len, bool angleInDegrees ) { CV_INSTRUMENT_REGION(); fastAtan32f_(Y, X, angle, len, angleInDegrees ); } #endif // CV_CPU_OPTIMIZATION_DECLARATIONS_ONLY CV_CPU_OPTIMIZATION_NAMESPACE_END }} // namespace cv::hal
宏CV_CPU_OPTIMIZATION_NAMESPACE_BEGIN定义在<opencv>/opencv2/core/cv_cpu_dispatch.h
#ifdef CV_CPU_DISPATCH_MODE
#define CV_CPU_OPTIMIZATION_NAMESPACE_BEGIN namespace __CV_CAT(opt_, CV_CPU_DISPATCH_MODE) {
#define CV_CPU_OPTIMIZATION_NAMESPACE_END }
#else
#define CV_CPU_OPTIMIZATION_NAMESPACE cpu_baseline
#define CV_CPU_OPTIMIZATION_NAMESPACE_BEGIN namespace cpu_baseline {
#define CV_CPU_OPTIMIZATION_NAMESPACE_END }
#define CV_CPU_BASELINE_MODE 1
#endif由于在文件层定义了CV_CPU_DISPATCH_MODE=AVX2,于是扩展后的CV_CPU_OPTIMIZATION_NAMESPACE_BEGIN。
namespace __CV_CAT(opt_, AVX2) {__CV_CAT也是个宏,它就是把两个参数以字符串的形式串起来。于是再次扩展后的CV_CPU_OPTIMIZATION_NAMESPACE_BEGIN。
namespace opt_AVX2 {到此能得出个结论,这里的fastAtan32f声明在了cv::hal::opt_AVX2命名空间。这里也没定义宏CV_CPU_OPTIMIZATION_DECLARATIONS_ONLY,于是也是在这个mathfuncs_core.simd.hpp完成了cv::hal::opt_AVX2::fastAtan32f函数实现。
参考
- OpenCV中的HAL方法调用流程分析 https://www.cnblogs.com/willhua/p/12521581.html