
chinese.cpp主要处理和汉字编码、拼音有关的任务。
一、资源包中文件
1.1 pingyin.rsp。
拼音包,放在cert目录下。为让用户可升级,一般放在userdata的cert目录。内容包括三类字符的中文发音:汉字、10个数字和26个英文字母。pingyin.rsp细节参考“拼音rsp:Tag3-H4=5(zipt_pinyin)”。
1.2 chinesepinyin.txt
一(0x4e00): yi1 丁(0x4e01): ding1|zheng1 丂(0x4e02): yu2 七(0x4e03): qi1 ......
文件是utf-8格式文本格式,手动编辑生成。
一行表示一个汉字。每一行依次是汉字、unicode编码、拼音。对拼音,依次是字母和数字表示的声调。字母全小写。声调只能是0到4,1表示1声调,2表示2声调,3表示3声调,4表示4声调,0表示轻声。
对unicode编码,第一行必须是0x4E00,最后一行是0x9FA5,中间的逐行加1。总共20902个汉字,具体是什么汉字参考“字体编辑用中日韩汉字Unicode编码表”。
一个拼音(包括字母和声调)最长不能超过7个ascii字符,有7个字符的像“床(0x5e8a): chuang2”。汉字中有像“兝(0x515d): gongfen”,不带声调就7个字符,认为是不支持发音的字符,为满足不能超过7,不要让带声调。(?集合中的最长拼音,有7个字母,那加上声音的最长拼音是8个字母。
对多音字,拼音部分用“|”隔开。最常见那个排在第一位。
该文件作用是用它生成chinesepinyin.code。
1.3 chinesepinyin.code
文件是二进制格式,它根据chinesepinyin.txt生成,而且只依赖它。生成方法:运行Rose Studio,“拼音”——chinesepinyin.code那一行,单击“文本转编码”。
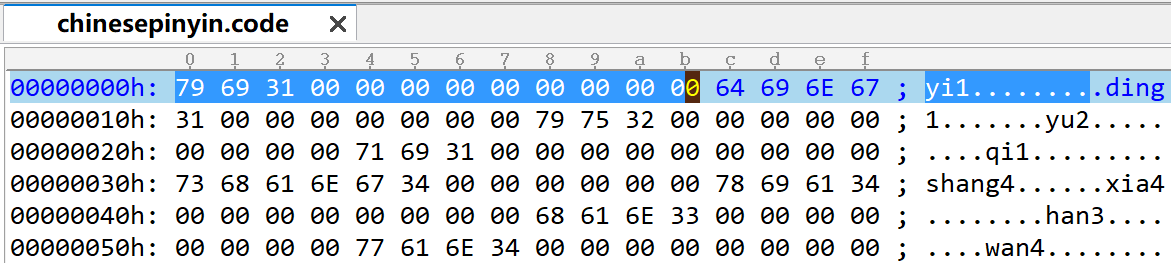
chinesepinyin.code就按着unicode码序,每个汉字12字节地存下去。由于每个汉字预留12字节,而且一个拼音最长7个字节,对每个汉字至少最后的5个字节值是'\0'。
只会保留第一个拼音。对多音字,已在生成chinesepinyin.txt要求最常用的放在首个,因而会保存最长用的。
总共20902个汉字,每汉字12字节,chinesepinyin.code文件长度250824字节。
base_instance::initialize()时,会加载chinesepinyin.code到变量pinyin_code,类型std::unique_ptr<char[]>。它是个内存块,尺寸250824字节,内容是chinesepinyin.code文件的原样复制。
<librose>/chinese.cpp
------
const char* pinyin(wchar_t wch)
{
if (wch < min_unicode || wch > max_unicode) {
// 必须保证参数wch在[0x4E00, 0x9FA5]内。
VALIDATE(false, err.str());
return nullptr;
}
return pinyin_code.get() + (wch - min_unicode) * fix_bytes_in_code;
}pinyin(wchar_t wch)指示了chinesepinyin.code文件作用,通过它,可由某个汉字unicode得到它最常用那个带声调的中文拼音。
1.4 chinesefrequence.txt
一(0x4e00) 丁(0x4e01) 七(0x4e03) 万(0x4e07) ......
文件是utf-8格式文本格式,手动编辑生成。
一行表示一个汉字。每一行依次是汉字、unicode编码。没有拼音。文件名中有“frequence”字样,存名思义,这文件收录常用汉字。
- gb2312[1th] chinese section. count: 3755
- gb2312[2th] chinese section. count: 3008
- 2个:啰(0x5570)、瞭(0x77ad)
3755+3008+2,总共6765个。
chinesefrequence.code作用是用它生成chinesefrequence.code。
1.5 chinesefrequence.code
文件是二进制格式。生成方法:运行Rose Studio,“拼音”——chinesefrequence.code那一行,单击“文本转编码”。
它根据chinesefrequence.txt生成,而且只依赖它,和有着完整汉字编码的chinesepinyin.txt无关。从chinesefrequence.txt提取出一个单元是unicode码(wchar_t)的数组,把这数组原样存储到文件,就是chinesefrequence.code。
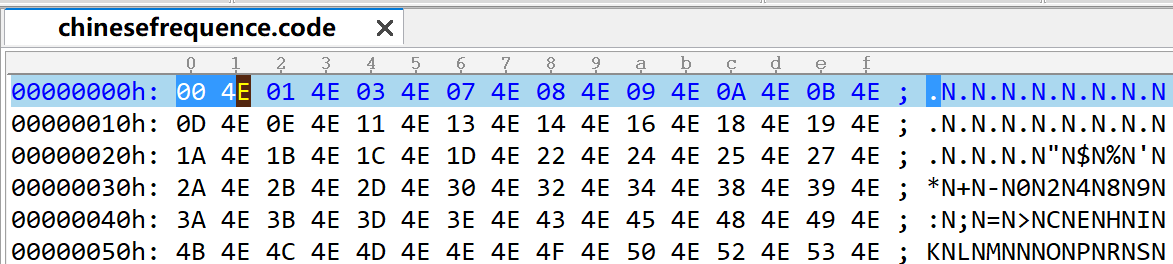
前两个字节“00 4E”,这是小端序,转到wchar_t值“0x4E00”,也就是chinesefrequence.txt中的第一个字符“一”。
总共6765个常用汉字,每汉字2字节,chinesefrequence.code文件长度13530字节。
chinesefrequence.code一个功能用于开发中文输入法。对输入法,一般不追求能支持所有汉字,一种选译就是这里给出的常用汉字集。
chinesefrequence.code是个汉字的unicode数组,以这里unicode值作为参数,调用pinyin(wch),便可得到该汉字最常用拼音,以它就可实现中文拼音输入法。
二、tpinyin::pump()
tpinyin::pump()是中文拼音子模块的时间片函数,它在app时间片内被调用。主要功能是把要播放utf-8格式文字转成声音,拼放入play_data_缓存。它会尽量把所有文字在一次pump()就全部放入。但文字难免很长,要是发现缓存中未播放字节数“>=low_threhold”,此次pump()会停止放入,并结束。后面文字等下一次pump。
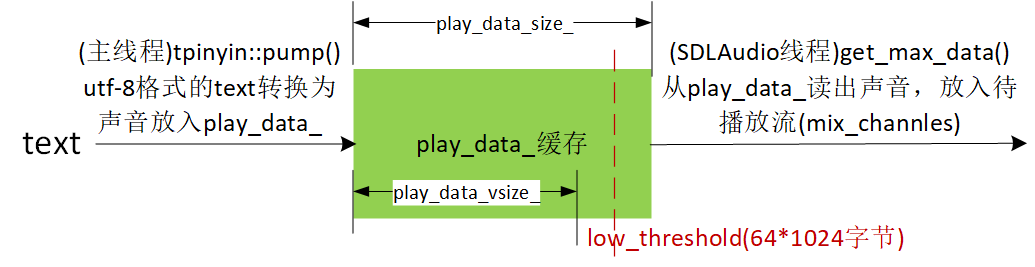
图3显示了play_data_缓存。主线程的tpinyin::pump()把utf-8格式的text转换为声音放入它,SDLAudio线程的get_max_data()则从它读出声音,放入声卡待播放流。play_data_size_表示play_data_缓存长度,它不是个固定值。那怎么控制缓存长度?——借用值是64K字节的low_threshold。text汉字被“逐个”放入缓存,放入一个后,就会判断当前填着的长度play_data_vsize_是不是“>=low_threshold”,一旦是,就不再放,等待SDLAudio线程的get_max_data()取走,直到play_data_vsize_小于low_threshold。由于有low_threshold在调控,缓存长度不会比low_threshold大太多。
这里存在两个结束时刻,一是tpinyin::pump()把text全部放入缓存(text_all_loaded是true),二是在第一点的基础上,SDLAudio线程读空了缓存,即同时play_data_vsize_等于0。is_speaking()返回false是要等到第二个时刻。
2.1 主逻辑
<librose>/chinese.cpp
------
void tpinyin::pump()
{
if (async_text_dirty_) {
...在非主线程调用speak(),便会让async_text_dirty_=true,这里会把非主线程提交的要播放内容async_text_同步到主线程的text。
}
if (text.empty()) {
return;
}text是当前要播放的内容。在一次speak过程,它不会随着已播放内容的变化而变化,变量curr_itor是text上的游标(读指针)。
const int low_threshold = 64 * 1024;
if (play_data_vsize_ >= low_threshold) {缓存中未播放字节数>=low_threhold,处在警戒线上。此次pump不做操作,等着SDLAudio线程从缓存读走更多数据。
return;
}
if (text_all_loaded) {
VALIDATE(curr_itor == utils::utf8_iterator::end(text), null_str);
if (play_data_vsize_ == 0) {
reset();
}text_all_loaded是true,意味着text内容已全部放入缓存。play_data_vsize_==0,意味着同时SDLAudio线程已读走全部数据,即可认为声卡播放完了,于是调用reset()结束此次speak(),内中会清空text。至此这次speak()彻底结束,is_speaking()将返回false。
return;
}
try {
if (unicodes[IDX_LAST] == 0) {
// first
curr_itor = text; // utils::utf8_iterator itor(text);
} else {
// second or later
++ curr_itor;
}
text_all_loaded = true;unicodes[IDX_LAST]是上一次pump放入缓存的最后一个字符编码,unicodes[IDX_LAST] == 0,表示是该次speak()的第一次pump,读指针curr_itor置为text头。如果是第二次或更后面pump,此时的curr_itor指向上一次pump已放入的最后一个字符,于是执行“++ curr_itor”,让此次pump从下一个字符开始放入。
for (; curr_itor != utils::utf8_iterator::end(text); ) {
wchar_t wch = *curr_itor;
.....for循环“逐个”扫描text中字符。针对不同类型字符,按不同规则处理,总之结果是放入play_data_缓存。“逐个”加引号,是因为放入并不是真的把text中字符一个个wch地放,放入时,可能会变换成其它字符,像增加。举个例子:123.32,那要读成“一百二十三点三二”,要增加本不存在的“千、十、点”,而“wch=1”这次,一次就会拿走“123.”这4个字符。
if (!is_digit) {
VALIDATE(pure_digits_ == 0, null_str);
}
if (play_data_vsize_ >= low_threshold) {
text_all_loaded = false;
break;放入当前字符后,缓存处在警戒线之上。避免缓存太大,此次pump就放到这里,后面的等下次pump。
这个“break”发生在“++ curr_itor”前,即此刻curr_itor指示的最后一个放入字符,所以前面刚进入“try”、不是第一次pump时,要“++ curr_itor”。
}
++ curr_itor;
}
} catch (utils::invalid_utf8_exception&) {
reset();text可能不是utf-8格式字符串,那会进入这里。
} }
2.2 播放数值
对文本“123.32”,要读成“一百二十三点三二”,而不是“一二三三二”。“12张”是读成“十二张”还是“一二张”。对出现的数字,得区分是单个数字读还是合成一个数值读。以下是用的几条规则。
- 数字后有小数点“.”,小数点后还有数字,认为是一个数值。
- 数字后跟有汉语量词时,认为是一个数值。——个人认为是不是跟着量词比较好判断(is_quantifier),于是选择默认是逐数字念。
- 对数值,整数部分最大12个数字,即可读的最大整数是“9999亿”。小数部分则没有限定数字数。对“1200000000000张”,会读成“一二千亿张”。轮到“1”时,以它开始有13个字符,超过12了,不认为是数值,于是单念。轮到“2”时,以它开始12个字符,而且后面跟的“张”是量词,认为是数值“二千亿”。
- “年”是量词,但如果前面数值在[1000, 2040]范围,认为不是数值。举个例子,“2023年”,不是读成“二千二十三年”,而是“二零二三年”。
pure_digits_用于指示接下有多少个数字要逐个读,即按纯数字看待,不要判断成数值。举个例子,对“123.32”,并不是扫描到“1”的那次、一次性把“一百二十三点三二”放入缓存,而是只放“一百二十三点”,小数部分“32”等着for的下一次扫描。这样扫到小数“3”时,一旦“32”后跟着量词,那就会错误读成“三十二”了。为避免这种情况,把pure_digits_设置2,表示紧接下的两个数字“3、2”一律逐个读。把“整数+点”和小数分开,这么设计的原因是没法预知小数最多会有几个字符,但又不能像处理整数一样给个“12”,毕竟很少会出现把超过“9999亿”的写成全数字。